
Base blockchain là giải pháp mở rộng Layer 2 của Coinbase được xây dựng trên OP Stack của Optimism. Base hiện tại có khá nhiều Node Providers, trong trường hợp không quá cần thiết thì bạn không nhất thiết phải dựng node riêng.
Chú ý: BaseNode được cập nhật liên tục về cả mã nguồn và cấu hình. Vì thế các hướng dẫn ở đây có thể không hoàn toàn trùng khớp với thực tế.
Mục lục
Hướng dẫn chạy fullnode cho Base blockchain
Để chạy Fullnode cho Base, đầu tiên bạn phải cài đặt docker:
// Cập nhật lại thông tin các gói cài đặt
sudo apt update && sudo apt upgrade -y
// Remove docker cũ
// Nếu bạn chưa cài docker trước đây thì bỏ qua lệnh này
sudo apt-get remove docker docker-engine docker.io containerd runc
// Cài đặt curl
// Nếu curl đã có sẵn thì bạn bỏ qua lệnh này
sudo apt install curl -y
// Cài đặt docker
curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.sh
// Xóa tệp cài đặt
rm get-docker.sh
// Cài đặt unzip nếu chưa có
sudo apt install unzip
// Cài đặt thư viện hỗ trợ build sourcecode
sudo apt install build-essentialTiếp theo bạn thực hiện các hướng dẫn dưới.
Hướng dẫn chạy Node cho Base blockchain không sử dụng snapshot
Chúng ta tạo một con EC2 trên Amazon cấu hình tầm 2 Core + 4G RAM + 200 HDD, cấu hình mạnh hơn thì càng tốt. Theo đề xuất đội dự án thì cần 16G RAM. Chi tiết hướng dẫn bạn xem tại: Base Node Opensource
Sau khi có EC2, chúng ta kết nối SSH tới server và thực hiện các lệnh sau:
# Clone base node từ Github
# Version thay đổi liên tục, bạn nên vào link sau để xem version mới nhất:
# https://github.com/base-org/node/tags
git clone https://github.com/base-org/node.git
mv node base-node
cd base-node
git checkout v0.8.0
# Sửa tệp .env.mainnet
# Cập nhật giá trị cho hai biến dưới
# Nên tạo một tài khoản trên https://www.ankr.com/rpc/dashboard và lấy rpc trên mạng Ethereum
# OP_NODE_L1_ETH_RPC
# OP_NODE_L1_BEACON
nano .env.mainnet
# Sửa tệp docker-compose.yml
// Uncomment dòng có .env.mainnet (Có 2 dòng)
# Tạo tệp .env
# Thiết lập giá trị cho biến trỏ tới thư mục chứa data
# Ví dụ trỏ tới: /home/ubuntu/base-node/data
# GETH_HOST_DATA_DIR=/home/ubuntu/base-node/data
// Chạy node
// Khi chạy hệ thống sẽ tự tải các thư viện và geth từ github để trong thư mục app
sudo docker compose up --build -d
// Start
sudo docker compose start
// Stop
sudo docker compose stop
// Xem log
sudo docker compose logs -n 100 -f
// Xóa node
sudo docker compose downBạn có thể xem danh sách các image chạy bằng lệnh:
// Lệnh xem danh sách images
sudo docker image ls
// Kết quả hiển thị như sau
REPOSITORY TAG IMAGE ID CREATED SIZE
base-node-geth latest 0e500721f4fa 2 weeks ago 1.2GB
base-node-node latest ec741f8da052 2 weeks ago 1.2GBSau khi chạy xong bạn có:
// RPC
http://localhost:8545/
http://<IP>:8545/
// Websocket
ws://localhost:8546/
ws://<IP>:8546/Một số lệnh test RPC:
// Xem fullnode có phải vẫn đang đồng bộ không
curl --data '{"jsonrpc":"2.0","method":"eth_syncing","params":[],"id":1}' -H "Content-Type: application/json" -X POST http://localhost:8545
// Lấy blocknumber mới nhất qua RPC
curl --data '{"method":"eth_blockNumber","params":[],"id":1,"jsonrpc":"2.0"}' -H "Content-Type: application/json" -X POST http://localhost:8545
// Lấy thông tin block mới nhất
curl --data '{"jsonrpc":"2.0","method":"eth_getBlockByNumber","params":["latest", false],"id":1}' -H "Content-Type: application/json" -X POST http://localhost:8545
// Lấy chainId
curl --data '{"method":"eth_chainId","params":[],"id":1,"jsonrpc":"2.0"}' -H "Content-Type: application/json" -X POST http://localhost:8545
// Lấy balance ETH
curl --data '{"method":"eth_getBalance","params":["0xf39Fd6e51aad88F6F4ce6aB8827279cffFb92266", "latest"],"id":1,"jsonrpc":"2.0"}' -H "Content-Type: application/json" -X POST http://localhost:8545
// Lấy thông tin giao dịch gửi lên blockchain
curl --data '{"method":"eth_getTransactionByHash","params":["0xafc19acfc376239cf8b4f881c2c0d529c4f204b880a82d4c540adab498903c91"],"id":1,"jsonrpc":"2.0"}' -X POST -H "Content-Type: application/json" http://localhost:8545
// Lấy thông tin giao dịch sau khi được xử lý trên blockchain
curl -X POST -H "Content-Type: application/json" --data '{"method":"eth_getTransactionReceipt","params":["0xafc19acfc376239cf8b4f881c2c0d529c4f204b880a82d4c540adab498903c91"],"id":1,"jsonrpc":"2.0"}' http://localhost:8545Thời điểm tháng 08/2023 tốc độ khá chậm khoảng 400,000 block / ngày, hiện tại đang 3M block, phải mất gần 8 ngày mới đồng bộ xong. Sau này tốc độ đồng bộ đã nhanh hơn.
Ta có thể check xem mất bao nhiêu lâu nữa bằng cách tạo tệp bash check-sync-status.sh nội dung như sau:
#!/bin/bash
echo "-------------------------------------"
time=$(date +"%Y-%m-%d %T" )
echo "Time to check: $time"
command -v jq &> /dev/null || { echo "jq is not installed" 1>&2 ; }
echo Latest synced block behind by: \
$((($( date +%s )-\
$( curl -s -d '{"id":0,"jsonrpc":"2.0","method":"optimism_syncStatus"}' -H "Content-Type: application/json" http://localhost:7545 |
jq -r .result.unsafe_l2.timestamp))/60)) minutesSau đó đánh lệnh sau để check:
// Chỉ chạy lần đầu tiên
sudo apt install jq
chmod +x check-sync-status.sh
// Check trạng thái đồng bộ
./check-sync-status.sh
// Xem trạng thái đồng bộ 15 phút một lần
while true; do ./check-sync-status.sh; sleep 15m; doneHướng dẫn chạy Node cho Base blockchain sử dụng Snapshot
Trước đây dự án mới bắt đầu (08/2023) còn chưa có snapshot, sau đó dự án có thông báo bản snapshot trong Message 1 trên Discord , nhưng không có hướng dẫn sử dụng snapshot này thế nào. Và tiếp sau đó là Message 2 trên Discord.
Bây giờ, dự án đã cập nhật chính thức trong tài liệu dự án. Sau này link đã thay đổi, cập nhật trên trang Base Node Snapshots. Hiện tại bản Snapshot ngày càng nặng, nên việc download về trước sau đó mới giải nén là không khả thi vì phải tốn gấp đôi dung lượng, do đó lãng phí tài nguyên. Chúng ta dùng lệnh sau để thực hiện tải và giải nén đồng thời:
# Mainnet
# Lệnh trên sẽ giải nén dữ liệu vào thư mục
# snapshots/mainnet/download
# Dữ liệu thực sự trong thư mục:
# snapshots/mainnet/download/geth
wget -qO- https://mainnet-full-snapshots.base.org/$(curl https://mainnet-full-snapshots.base.org/latest) | tar xvz
# Testnet
wget-qO- https://sepolia-full-snapshots.base.org/$(curl https://sepolia-full-snapshots.base.org/latest) | tar xvzThông thường, dữ liệu bản backup là vào ngày thứ 7 hàng tuần, tệp snapshot mới nhất sẽ có khoảng thứ 4 hàng tuần.
- Cập nhật ngày 2024-07-02: Bản snapshot mới nhất không còn ở định dạng .tar mà là định dạng mới .tar.zst => Vì thế lệnh vừa tải vừa giải nén không còn hoạt động nữa. Chúng ta phải thực hiện hai bước:
wget https://mainnet-full-snapshots.base.org/$(curl https://mainnet-full-snapshots.base.org/latest)
tar –zstd -xvf base-mainnet-full-1719815348.tar.zst
Sau khi tải và giải nén xong, ta sửa tệp .env để cập nhật lại đường dẫn đến bản snapshot:
# Trỏ trực tiếp tới thư mục chứa dữ liệu snapshot
GETH_HOST_DATA_DIR=/home/ubuntu/base-node/snapshots/mainnet/downloadBay giờ chúng ta chạy lại Node bằng lệnh:
// Chạy node
sudo docker compose up -d
// Start
sudo docker compose start
// Stop
sudo docker compose stop
// Xem log
sudo docker compose logs -n 100 -f
// Xóa node
sudo docker compose downKhi node chạy xong, check lại blocknumber ở 2024174. Chạy tệp check-sync-status.sh để kiểm tra thì báo:
Latest synced block behind by: 30882 minutesTức là block mới nhất cách hiện tại khoảng 21 ngày nữa, với tốc độ sync bằng 10 lần tốc độ sinh block mới, thì đầu đó mất từ 2 ngày đến 3 ngày. Tốc độ này tùy từng phiên bản ở mỗi thời điểm khác nhau sẽ khác nhau.
Các bước thực hiện đồng bộ dữ liệu của BaseNode
Qua thời gian kiểm tra log và xử lý một số lỗi phát sinh liên quan tới BaseNode thì mình thấy luồng đồng bộ của BaseNode như sau:
- B1: Walking back L1Block by hash
Lần đầu khi chạy Node, hệ thống sẽ lấy thông tin block L1 hiện tại, từ đó lấy verify ngược lại tới “Finalized block“. Nếu verify lỗi thì chứng tỏ dữ liệu có vấn đề, verify thành công sẽ chuyển sang bước 2. Log có dạng:
node-1 | t=2024-04-22T07:17:33+0000 lvl=info msg=”Walking back L1Block by hash” curr=0xfa8362c86309039fd06ecc3fd7d61c1b134487c938a2f9b56d0f9234557ecb64:19701201 next=0xf07202e6e6e32ca0a1e671b29d678d2567e21c3eb991d4fd8c4762230db71e1c:19701200 l2block=0xce7f787d33d65f2227356cf0f22d6f5d3ae439920758ef525156969b1591eb40:13441083 - B2: Sync progress
Bước này sẽ thực hiện đồng bộ dữ liệu L1 bắt đầu từ “Finalized Block” đến block mới nhất trên L1. Sau khi thực hiện xong chuyển sang B3. Log có dạng:
node-1 | t=2024-04-22T08:04:04+0000 lvl=info msg=”Sync progress” reason=”reconciled with L1″ l2_finalized=0xe7363bac1ff22bb96bcf9dff2acd43885c3967eb3bf409ca9255787071288d0d:13437755 l2_safe=0x3241c1457d80ae6a6ecd7f3d4bda602b15589e9572d858a05b338cff775db345:13438026 l2_pending_safe=0x500942c05bb2e71ea5a5cc5e604e27d8a6b50a2b91e9d325eec944ea5e96e288:13438033 l2_unsafe=0xf323d1c128bf33a6bb0d5a3f2d8b20d3b0a8ff6b09d385758f3d078e596c7c3a:13489486 l2_time=1713768319 l1_derived=0xb4c724083dabe74a2b4e4da6720e05ce44301ecda98a84e2cfffbd31a3a68d3f:19700729 - B3: Chain head was updated
Bước này sẽ thực hiện sinh dữ liệu cho L2 và cập nhật lại “Finalized Block”. Mỗi lần cập nhật Log có dạng:
geth-1 | INFO [04-22|07:31:35.345] Chain head was updated number=13,489,463 hash=f9a074..6c226c root=f47325..eb246b elapsed=2.59319ms age=47m2s - B4: Đồng bộ dữ liệu realtime
Giai đoạn này dữ liệu “Finalized Block” và L2 sẽ được cập nhật liên tục theo thời gian thực từ L1 RPC và P2P Node- Việc đồng bộ và sinh dữ liệu L2 từ L1 RPC sẽ sinh ra các “Finanlized Block” mới, nhưng các “Finalized Block” thường trễ so với thời gian thực từ 1 đến 2 phút.
- Đồng bộ dữ liệu từ các P2P khác cho ra dữ liệu L2 mới nhất gần như real time nhưng nó không phải là “Finalized Block”. Và để đảm bảo chính xác hệ thống sẽ cần thêm đoạn tính toán để verify từ “Finalized Block” đến block hiện tại. Tùy theo cấu hình server hoặc khoảng cách từ “Finalized Block” đến Block hiện tại mà việc này có thể mất nhiều hay ít thời gian.
- Log khi này sẽ có dạng như dưới (Không còn thông tin age nữa):
geth-1 | INFO [04-23|15:49:17.596] Chain head was updated number=13,549,005 hash=e9607b..224547 root=d7171b..7dad73 elapsed=2.192809ms
Một số vấn đề phát sinh khi chạy node
Tại sao sau khi chạy BaseNode, thời gian đầu delay time vẫn tăng
“Delay Time” được mình định nghĩa là khoảng thời gian từ block cuối cùng mà BaseNode đồng bộ được đến thời gian hiện tại. Thời gian này nhỏ hơn 1 phút thì coi như Base Node đã được đồng bộ.
Nếu bạn tải snapshot về và giải nén thì đâu đó mất tầm gần 1 ngày rùi, do đó khi chạy BaseNode thì “Delay Time” đâu đó tầm 18h. Nhưng điều lạ là sau khi chạy xong, thấy log bình thường không có lỗi, nhưng trong vòng 1h đến 3h sau đó “Delay Time” không giảm mà lại tiếp tục tăng, sau khoảng thời gian này thì “Delay Time” mới giảm. Tại sao lại như vậy?
Sau khi check log thì tôi thấy, Quá trình đồng bộ gồm 2 bước:
- B1: Generating state snapshot
Ở giai đoạn này bạn sẽ thấy log đại loại như sau:
base-node-geth-1 | INFO [01-12|03:39:36.697] Generating state snapshot root=14962a..b0b44b in=be67e4..e9fca9 at=25c084..d1db5a accounts=41,692,572 slots=87,098,775 storage=8.73GiB dangling=0 elapsed=1h54m24.893s eta=39m24.932s
Đoạn này giống kiểu, Node lấy từng khối (Batch) dữ liệu và lưu lại Client. Ở bước này, khi eta giảm về 0 thì sẽ chuyển sang bước 2. Ở giai đoạn này, chưa cập nhật thông tin block, mà mới tải dư liệu về, vì thế “Delay Time” vẫn tiếp tục tăng. - B2: Chain head was updated
Ở giai đoạn này Node bắt đầu cập nhật dữ liệu blockchain. Log dạng:
base-node-geth-1 | INFO [01-12|09:10:39.495] Chain head was updated number=9,108,827 hash=3fb912..d5bb7f root=da96b3..b005d1 elapsed=”90.647µs” age=12h7m18s
base-node-geth-1 | INFO [01-12|09:10:51.259] Chain head was updated number=9,108,828 hash=9ff24e..3202dc root=124f29..78ffc5 elapsed=”101.479µs” age=12h7m28s
Không đủ SSD khi giải nén tệp snapshot
Tệp snapshot khá lớn và tăng dần theo thời gian, vì thế để có thể chạy được thì ít nhất ổ cứng SSD của bạn phải có dung lượng trên 2.2 lần so với dữ liệu hiện tại, bởi vì khi đang giải nén dữ liệu thì gồm dữ liệu đã giải nén và tệp nén. Nhiều khi bạn không lường được dữ liệu là bao nhiêu, nên trong quá trình giải nén có thể làm đầy SSD của bạn.
Trong trường hợp bạn thấy sắp đầy ổ cứng, bạn vào EC2, chọn Instance tương ứng, vào Storage chọn Volume ID tương ứng, sau đó thực hiện “Modify Volume” để tăng dung lượng lên. Sau khi tăng xong, bạn thấy hệ điều hành vẫn chưa cập nhật volume mới. Của tôi dung lượng ban đầu là 1.3T, sau đó tăng lên 1.6T nhưng hệ điều hành chưa cập nhật volume, có thể kiểm tra bằng lệnh:
df -h
--------------------
Filesystem Size Used Avail Use% Mounted on
/dev/root 1.3T 1.1T 140G 89% /
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 1.6G 892K 1.6G 1% /run
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/xvda15 105M 6.1M 99M 6% /boot/efi
tmpfs 795M 4.0K 795M 1% /run/user/1000Giờ bạn dùng lệnh sau để xem thông tin các phân vùng:
sudo lsblk
--------------------
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 24.4M 1 loop /snap/amazon-ssm-agent/6312
loop1 7:1 0 55.6M 1 loop /snap/core18/2745
loop2 7:2 0 63.3M 1 loop /snap/core20/1879
loop3 7:3 0 111.9M 1 loop /snap/lxd/24322
loop4 7:4 0 53.2M 1 loop /snap/snapd/19122
loop5 7:5 0 40.8M 1 loop /snap/snapd/20092
loop6 7:6 0 55.7M 1 loop /snap/core18/2790
loop7 7:7 0 63.5M 1 loop /snap/core20/2015
loop8 7:8 0 24.6M 1 loop /snap/amazon-ssm-agent/7528
xvda 202:0 0 1.6T 0 disk
├─xvda1 202:1 0 1.3T 0 part /
├─xvda14 202:14 0 4M 0 part
└─xvda15 202:15 0 106M 0 part /boot/efiBạn thấy xvda là SSD của bạn, trên Ubuntu nó tương đương với đường dẫn /dev/xvda
Còn xvda1 là phân vùng 1 của ổ xvda, bạn chú ý số 1 này. Như vậy chúng ta cần mở rộng dung lượng cho phân vùng 1 bằng lệnh sau:
# Cập nhật dung lượng cho phân vùng 1
sudo growpart /dev/xvda 1
# Check lại phân vùng đã cập nhật
sudo lsblk
--------------------
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 24.4M 1 loop /snap/amazon-ssm-agent/6312
loop1 7:1 0 55.6M 1 loop /snap/core18/2745
loop2 7:2 0 63.3M 1 loop /snap/core20/1879
loop3 7:3 0 111.9M 1 loop /snap/lxd/24322
loop4 7:4 0 53.2M 1 loop /snap/snapd/19122
loop5 7:5 0 40.8M 1 loop /snap/snapd/20092
loop6 7:6 0 55.7M 1 loop /snap/core18/2790
loop7 7:7 0 63.5M 1 loop /snap/core20/2015
loop8 7:8 0 24.6M 1 loop /snap/amazon-ssm-agent/7528
xvda 202:0 0 1.6T 0 disk
├─xvda1 202:1 0 1.6T 0 part /
├─xvda14 202:14 0 4M 0 part
└─xvda15 202:15 0 106M 0 part /boot/efi
# Nhưng hệ điều hành vẫn chưa cập nhật, vẫn là 1.3T
df -hT
--------------------
Filesystem Type Size Used Avail Use% Mounted on
/dev/root ext4 1.3T 570G 691G 46% /
tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs tmpfs 1.6G 1.1M 1.6G 1% /run
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/xvda15 vfat 105M 6.1M 99M 6% /boot/efi
tmpfs tmpfs 795M 4.0K 795M 1% /run/user/1000Do kiểu filesystem là ext4 lên bạn phải dùng thêm lệnh sau để cập nhật dung lượng:
# Cập nhật dung lượng trên Hệ điều hành
sudo resize2fs /dev/xvda1
--------------------
resize2fs 1.46.5 (30-Dec-2021)
Filesystem at /dev/xvda1 is mounted on /; on-line resizing required
old_desc_blocks = 163, new_desc_blocks = 200
The filesystem on /dev/xvda1 is now 419401979 (4k) blocks long.
# Kiểm tra lại, đã cập nhật 1.6T
df -hT
--------------------
Filesystem Type Size Used Avail Use% Mounted on
/dev/root ext4 1.6T 570G 981G 37% /
tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs tmpfs 1.6G 1.1M 1.6G 1% /run
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/xvda15 vfat 105M 6.1M 99M 6% /boot/efi
tmpfs tmpfs 795M 4.0K 795M 1% /run/user/1000Lỗi không thể đồng bộ được node (Stuck syncing)
Ban đầu tôi tạo node sử dụng EC2 bên Oregon, mọi việc khá thuận lợi. Nhưng sau đó chuyển node sang EC2 bên Virginia thì không hiểu sao không thể đồng bộ được, lỗi này được mô tả trong Issue: Stuck syncing, sau đó dự án sửa bằng cằng cập nhật tài liệu hướng dẫn Add hardware requirements, snapshots instrux and EBS callout to Node guide. Thời gian block cuối cùng đến hiện tại cứ tăng dần lên, tức là tốc độ đồng bộ còn chậm hơn cả tốc độ sinh block mới, dùng check-sync-status.sh để đo thấy thời gian tăng dần lên, dường như không bao giờ có thể hoàn thành đồng bộ:
Time to check: 2023-09-19 10:43:45
Latest synced block behind by: 1032 minutes
-------------------------------------
Time to check: 2023-09-19 10:58:45
Latest synced block behind by: 1020 minutes
-------------------------------------
Time to check: 2023-09-19 11:13:46
Latest synced block behind by: 1019 minutes
-------------------------------------
Time to check: 2023-09-19 11:43:46
Latest synced block behind by: 1030 minutes
-------------------------------------
Time to check: 2023-09-19 13:29:02
Latest synced block behind by: 1069 minutes
-------------------------------------
Time to check: 2023-09-19 13:44:07
Latest synced block behind by: 1073 minutes
-------------------------------------
Time to check: 2023-09-19 13:59:10
Latest synced block behind by: 1074 minutes
-------------------------------------
Time to check: 2023-09-19 14:14:10
Latest synced block behind by: 1070 minutesKiểm tra log node thấy hay bắn warning:
base-node-node-1 | t=2023-09-19T10:40:46+0000 lvl=warn msg="Failed to share forkchoice-updated signal" state="&{HeadBlockHash:0x2dd80513c3f4c954b469ac3935feea5c9f9bb74e0381ab2817e7c604989351a6 SafeBlockHash:0x2dd80513c3f4c954b469ac3935feea5c9f9bb74e0381ab2817e7c604989351a6 FinalizedBlockHash:0x504af924e026880c56992f4efde5e016a8493375645eb635b2dd5f47f11280e8}" attr="&{Timestamp:0x6508881f PrevRandao:0xca73e67ad270d886396e27f89d1fb4143a68c53b8606856b22cc90b2710e12ee SuggestedFeeRecipient:0x4200000000000000000000000000000000000011 Transactions:[0x7ef90159a0ddf3d36766b23572ac0ca45729cff3aa438b912fc879f70a639c47772ada633f94deaddeaddeaddeaddeaddeaddeaddeaddead00019442000000000000000000000000000000000000158080830f424080b90104015d8eb90000000000000000000000000000000000000000000000000000000001152a3d0000000000000000000000000000000000000000000000000000000065088797000000000000000000000000000000000000000000000000000000073bf3882e69f036d5d59619b9d9b0c00df8112f9c3eac226113d3d503c7718d6b109c1b8600000000000000000000000000000000000000000000000000000000000000000000000000000000000000005050f69a9786f081509234f1a7f4684b5e5b76c900000000000000000000000000000000000000000000000000000000000000bc00000000000000000000000000000000000000000000000000000000000a6fe0 0x7ef90227a003b15add2088cd77f276da3d15b6b3fabed5e5bbc7cfe7f22aa5c7cd247279e094977f82a600a1414e583f7f13623f1ac5d58b1c0b944200000000000000000000000000000000000007876a94d74f430000876a94d74f4300008304658880b901c4d764ad0b0001000000000000000000000000000000000000000000000000000000018d8c0000000000000000000000003154cf16ccdb4c6d922629664174b904d80f2c350000000000000000000000004200000000000000000000000000000000000010000000000000000000000000000000000000000000000000006a94d74f430000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000c000000000000000000000000000000000000000000000000000000000000000c41635f5fd000000000000000000000000f8ce08466c86e90600bb0f5263b610fb9e5e7152000000000000000000000000a541b05f878329b3d10bed978d63a5fe32cecb20000000000000000000000000000000000000000000000000006a94d74f4300000000000000000000000000000000000000000000000000000000000000000080000000000000000000000000000000000000000000000000000000000000000b77281eaecb20000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 0xf9026f83103ffd8407839ac38302362794aab5a48cfc03efa9cc34a2c1aacccb84b4b770e480b902046c459a2800000000000000000000000038de71124f7a447a01d67945a51edce9ff4912510000000000000000000000000000000000000000000000000000000000000080000000000000000000000000000000000000000000000000000000006508dc7d00000000000000000000000000000000000000000000000000000000000001400000000000000000000000000000000000000000000000000000000000000084704316e5000000000000000000000000000000000000000000000000000000000000006f93ab8d764cac5e1372b261a90865a8b2e0b8cda9e3d95bd8387c27347a34318e000000000000000000000000000000000000000000000000000000000000001493ab8d764cac5e1372b261a90865a8b2e0b8cda9e3d95bd8387c27347a34318e0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000821110eb9e10e520159839642804323d30e2236542fabb87cb30a1d42b6a2b057873cf849e83210583c3aaf1505a41a93a32a9a2eed712a12ead91b2aaed208e5c1c0df5ba627cb650abcac992f263c62ab57af4432e78d5c190e31cf345d8f41bd31ee2df3b323eb15c6a569ddd40f186ece1f80d4d04c7a5dc187c8d825c2cebba1c00000000000000000000000000000000000000000000000000000000000082422ea08d045faec4ebdc63d0347afb63035cdad671bc106b2f209abd0af1fb5a2f6e35a052aac62a178b1d18372d6a74ceef4d841bc9cc1e28b91e9ba774b6d6b3d4676f 0x02f8bb82210582022f8405f5e100845a0562d8830156ef94cf205808ed36593aa40a44f10c7f7c2f67d4a4d487a51cc429efb000b8446945b123000000000000000000000000a63e466faaa29e7288f290d2e81e21587b9b98db0000000000000000000000000000000000000000000000000000000000000001c001a0ea6ec514394a532e90be47b59ccb487001230fb5f130a977d500c48d253c49c1a041529d4455534f36469f193a5eb6d909e1a7b831b862ae017fc3fd1b52180653 0x02f8b2822105648405f5e100845a0562d88301313594cf205808ed36593aa40a44f10c7f7c2f67d4a4d480b844b51d053400000000000000000000000005f92318b0d0b588a237ec49a7179ab9c58864000000000000000000000000000000000000000000000000000000000000000001c001a01da56e42b5793fe8e384890495a92237f832b1910d5be2fbf62bcdd3880cd9b0a0622174bf32e35ba0e2157f5e18e31971cfa29dff40ae85ae46fbabb41786ec7c 0x02f8bb8221058205dd8405f5e100845a0562d8830156ef94cf205808ed36593aa40a44f10c7f7c2f67d4a4d487186cc6acd4b000b8446945b123000000000000000000000000ea7b37c517998e28acca2184b386a75f79991d920000000000000000000000000000000000000000000000000000000000000001c001a0739eb7a6c35c2178c6445184cdfc21111ba40652878c6cd9618cb35b56784c41a071166624a253d9bdb843766d7e9199cf986d64d220cba46794c856ea9ab262ee 0x02f8d6822105830102168405f5e0ff8502540be400830249f094ff231524719db94a0ef08a88fc4e6939134eade880b864eca0ca01000000000000000000000000b1964a4a2672b6bbc3c6358ec70a14c1468139b60000000000000000000000000000000000000000000000000000000000000028000000000000000000000000000000000000000000000000d02ab486cedc0000c001a06785418b6eb17c13a146fe3f72a87649a436c0160e6ba4a6dbd074f8dd062d59a05eb9938491ee69d1e54595723df87b26c0b38b9c741206f24c36ffcbc8dd559d 0x02f8908221058281ef8405f5e0ff8502540be400830557309488e6aeb90795f586542b4062cb9f853a5582966c80a0000000000000000000001e28b1964a4a2672b6bbc3c6358ec70a14c1468139b6c001a0d1086d202b6c6efd78824c17ae91cabce5c8b0c115788cb8a0fec174bcf5c53fa071a4e4d4190e247eb1d5777d3f5659fea1d02d8cd6f461421eeabb9a5f1a5fb7 0x02f8f4822105822639839c3cdc839c3cdc830830d7940000000000cc2f88402b31ca4045f37bf79f3e5980b8860000000003000006d47267f8757b251a2d088964a3ec466762d6e0eb42000000000000000000000000000000000000060003304da90d2bd672c2fd4a7aad55176ab27417f71eeb466342c4d449bc9f53a865d5cb90586f40521500154c36388be6f416a29c8d8eee81c771ce6be14b18d9aaec86b65d86f6a7b5b1b0c42ffa531710b6ca0015c001a0cde42beede839201228bf1912e067e7b4eea2e31496f50b9363f6cc9d04b6c66a01db57802c6cb613f242afbb1ffafc4f8789880da307b7a42f85c627c7e32d601 0x02f8b282210581b1830186a0834c4b408401318230940000000000771a79d0fc7f3b7fe270eb4498f20b80b8448973e2cb000000000000000000000000000000000000000000000000000000000000006400000000000000000000000000000000000000000000000000000000000000b0c001a00e7acef7ba8076eadeacc8435a87cac7f06d1e264e0fc5b0861d71d834a4e36ca07d24230a4833f08f5bd4616b13b4e70d4b53f2c95cfc51374582217171d9a33a] NoTxPool:true GasLimit:0x1c9c380}" err="Post \"http://geth:8551\": context deadline exceeded"
base-node-node-1 | t=2023-09-19T10:40:46+0000 lvl=warn msg="Derivation process temporary error" attempts=1 err="engine stage failed: temp: temporarily cannot insert new safe block: failed to create new block via forkchoice: Post \"http://geth:8551\": context deadline exceeded"Tưởng do lỗi này lên mới gây ra hiện tượng trên nhưng không phải. Node cũ trên Oregon tôi thử tắt nó 30 phút và đồng bộ lại thấy vẫn bắn lỗi này nhưng sau đó vẫn đồng bộ được. Tôi thấy Disk vẫn còn trong nhiều, CPU dùng rất ít, mà trên Oregon tôi chỉ dùng EC2 t2.xlarge (2 vCPU + 4G RAM + 1T Storage gp3) chạy bình thương.
Tôi đã thử các giải pháp khác nhau:
- C1: Cài đặt node mới, tải snapshot mới nhất về, sau khi xong mọi thời thì thời gian từ block cuối c ùng đến hiện tại trễ tầm 9h
- Thử với các RPC layer 1 khác nhau:
- https://rpc.ankr.com/eth, https://ethereum.publicnode.com/ và https://ethereum.blockpi.network/v1/rpc/public => Vấn đề không được giải quyết
Tôi kiểm tra điều thú vị là thời gian ping server Virginia tới các rpc trên còn nhanh hơn cả bên Oregon. - Dùng RPC của Alchemy nhưng bị block ngay lần chạy đầu tiên
- https://rpc.ankr.com/eth, https://ethereum.publicnode.com/ và https://ethereum.blockpi.network/v1/rpc/public => Vấn đề không được giải quyết
- Uncomment dòng dưới trông tệp .env.mainnet để tăng tốc độ nhưng cũng không thành công
OP_NODE_L1_TRUST_RPC=true - Chuyển đổi source sang tag v0.3.0 (Oregon đang dùng) và sang tag mới nhất v0.3.1-rc.3, build và chạy lại nhưng cũng không thành công
- Thử với các RPC layer 1 khác nhau:
- TH2: Tôi quyết định clone toàn bộ server từ Oregon sang Virginia (Xem hướng dẫn: Di chuyển / Sao chép server EC2 từ vùng này sang vùng khác)
- Sau khi clone xong và chạy lại thì thời gian từ block cuối cùng đến hiện tại trễ tầm 6h. Mặc dù giảm được 3h độ trễ nhưng kết quả vẫn tương tự.
- Tôi nghĩ rằng nếu mình để độ trễ tầm dưới 1h khả năng sẽ thành công. Thế là sau khi clone server xong, tôi không đồng bộ ngày mà sử dụng rsync để đồng bộ dữ liệu qua lệnh:
rsync -avzu ubuntu@<IP>:/home/ubuntu/base-node/data/geth/chaindata /home/ubuntu/base-node/data/geth
Thực hiện liên tục nhiều lần như vậy, lần đầu lâu, lần sau sẽ nhanh dần lên, thấy dữ liệu đồng bộ thì lúc đó tắt tạm Node trên server Oregon đi và rsync lần cuối cùng. Sau khi xong bật đồng thời cả hai server lên, cả hai server lúc này dữ liệu đều trễ chỉ có 5 phút, nhưng điều lạ là server bên Oregon thì sau 30 phút là đồng bộ hoàn toàn, còn server Virginia thì thời gian trễ càng ngày càng tăng
Như vậy, vấn đề không phải do độ trễ dài, không phải do rpc của L1, không phải do cấu hình hay bản source code. Tôi quyết định kiểm tra log kỹ hơn. Bạn dùng lệnh sau để kiểm tra sẽ thấy tốc độ cập nhật 1 block mất 4s, trong khi thời gian sinh ra 1 block là 2s, điều đó chứng tỏ tốc độ đồng bộ chậm gấp 2 lần so với tốc độ sinh block mới:
sudo docker compose logs -n 100 -f | grep "Chain head was updated"
-----------------------------------
base-node-geth-1 | INFO [09-23|02:47:48.528] Chain head was updated number=4,306,166 hash=57daa7..0e9573 root=fa5ca9..279294 elapsed="412.504µs" age=9h53m9s
base-node-geth-1 | INFO [09-23|02:47:49.800] Chain head was updated number=4,306,167 hash=9ea9db..8594e8 root=bd87a4..399f82 elapsed="383.525µs" age=9h53m8s
base-node-geth-1 | INFO [09-23|02:49:04.419] Chain head was updated number=4,306,168 hash=5dc5fb..65116d root=e6762b..60f5ac elapsed="860.713µs" age=9h54m21s
base-node-geth-1 | INFO [09-23|02:49:05.386] Chain head was updated number=4,306,169 hash=f40201..cbcb63 root=37dfdd..fde802 elapsed="336.339µs" age=9h54m20s
base-node-geth-1 | INFO [09-23|02:49:05.900] Chain head was updated number=4,306,170 hash=3ec45d..c2893a root=3522c4..021df2 elapsed="490.318µs" age=9h54m18s
base-node-geth-1 | INFO [09-23|02:49:06.783] Chain head was updated number=4,306,171 hash=9041b0..4c9191 root=7291a6..30afd1 elapsed="499.968µs" age=9h54m17s
base-node-geth-1 | INFO [09-23|02:49:07.316] Chain head was updated number=4,306,172 hash=7c674a..aa0c1a root=899d32..f6447c elapsed="259.733µs" age=9h54m16s
base-node-geth-1 | INFO [09-23|02:49:07.492] Chain head was updated number=4,306,173 hash=b6b1c0..a44f0f root=11086f..a4b176 elapsed="336.656µs" age=9h54m14s
base-node-geth-1 | INFO [09-23|02:49:08.411] Chain head was updated number=4,306,174 hash=4a25cc..1b6344 root=6fa1e8..5ba100 elapsed="332.255µs" age=9h54m13sKiểm tra log kỹ hơn bằng lệnh dưới, thấy rất hay gặp trường hợp “Aborting state snapshot generation” và phải “Resuming state snapshot generation“:
sudo docker compose logs -n 100 -f | grep "base-node-geth-1"
-----------------------------------
base-node-geth-1 | INFO [09-23|03:17:18.638] Chain head was updated number=4,306,336 hash=4c4f08..af6322 root=385228..5711cf elapsed="440.574µs" age=10h16m59s
base-node-geth-1 | INFO [09-23|03:17:18.676] Starting work on payload id=0xbe501be462b298e0
base-node-geth-1 | INFO [09-23|03:17:18.978] Aborting state snapshot generation root=272a32..073bd5 at=427ebd..cd2921 accounts=6,148,822 slots=7,052,752 storage=928.37MiB dangling=0 elapsed=2h19m59.335s eta=6h38m57.339s
base-node-geth-1 | INFO [09-23|03:17:18.978] Resuming state snapshot generation root=6bc263..e80aaa at=427ebd..cd2921 accounts=6,148,822 slots=7,052,752 storage=928.37MiB dangling=0 elapsed=2h19m59.335s eta=6h38m57.339s
base-node-geth-1 | INFO [09-23|03:17:18.983] Imported new potential chain segment number=4,306,337 hash=a6b753..2c7069 blocks=1 txs=10 mgas=1.236 elapsed=303.842ms mgasps=4.069 age=10h16m57s dirty=0.00B
base-node-geth-1 | INFO [09-23|03:17:18.985] Chain head was updated number=4,306,337 hash=a6b753..2c7069 root=031d49..108edc elapsed="334.095µs" age=10h16m57s
base-node-geth-1 | INFO [09-23|03:17:20.585] Starting work on payload id=0x2627ce16e7d58b6d
base-node-geth-1 | INFO [09-23|03:17:20.738] Aborting state snapshot generation root=6bc263..e80aaa at=42834f..3a186b accounts=6,150,490 slots=7,052,960 storage=928.49MiB dangling=0 elapsed=2h20m1.095s eta=6h38m53.674s
base-node-geth-1 | INFO [09-23|03:17:20.738] Resuming state snapshot generation root=4799a9..558b93 at=42834f..3a186b accounts=6,150,490 slots=7,052,960 storage=928.49MiB dangling=0 elapsed=2h20m1.095s eta=6h38m53.674s
base-node-geth-1 | INFO [09-23|03:17:20.742] Imported new potential chain segment number=4,306,338 hash=6ac1b0..86c983 blocks=1 txs=14 mgas=3.867 elapsed=153.458ms mgasps=25.198 age=10h16m57s dirty=0.00B
base-node-geth-1 | INFO [09-23|03:17:20.744] Chain head was updatedDự đoán có thể liên quan tới tốc độ đọc ghi disk lên tôi quyết định kiểm tra thông số này trên 2 server:
# Server Oregon (Đồng bộ OK)
# Sử dụng storage GP3
sudo hdparm -Tt /dev/xvda
------------------------------------
/dev/xvda:
Timing cached reads: 19108 MB in 1.99 seconds = 9612.10 MB/sec
Timing buffered disk reads: 466 MB in 3.00 seconds = 155.21 MB/sec
------------------------------------
# Server Virginia (Không đồng bộ được)
# Sử dụng storage GP3
sudo hdparm -Tt /dev/xvda
------------------------------------
/dev/xvda:
Timing cached reads: 18140 MB in 1.99 seconds = 9120.76 MB/sec
Timing buffered disk reads: 42 MB in 3.56 seconds = 11.79 MB/sec
------------------------------------Như vậy tốc độ “Timing buffered disk reads” trên Oregon nhanh hơn gấp 10 lần trên Virginia, mặc dù Virginia và Oregon cùng kiểu Storage GP3. Tôi thử tạo Instance khác trên Virginia sử dụng Storage GP2 thấy tốc độ tốt hơn hẳn:
# Server Virginia
# Sử dụng storage GP2
sudo hdparm -Tt /dev/xvda
------------------------------------
/dev/xvda:
Timing cached reads: 20970 MB in 1.99 seconds = 10550.24 MB/sec
Timing buffered disk reads: 242 MB in 3.01 seconds = 80.51 MB/sec
------------------------------------Tôi quyết định chuyển đổi Storage trên Virginia từ GP3 sang GP2 => Khi bắt đầu chạy thời gian trễ từ block cuối cùng đến hiện tại tầm 9h, sau đó tăng lên 15h, rùi bắt đầu giảm. Sau hơn 30h thì node đã đồng bộ hoàn toàn.
Node hay bị tình trạng Delay
Sau thời gian sử dụng, tôi thấy rằng Node trên Base rất hay bị delay, thời gian có thể lên đến hàng giờ, sau đó lại trở về bình thường. Việc này xảy ra ở thời điểm ngẫu nhiên, nhưng cũng tương đối thường xuyên.
Sau thời gian theo dõi tôi thấy, ở các thời điểm này CPU và RAM sử dụng không nhiều, như vậy vấn đề không phải do CPU và RAM. Tôi đã quyết định đo thông tin đọc ghi Storage ở thời điểm này bằng lệnh:
# Cài đặt lần đầu
sudo apt install sysstat
# Thực hiện đo
iostat
# Thực hiện đo tốc độ đọc ghi disk, cứ 30s lại cập nhật 1 lần
iostat -d 30Dữ liệu tôi đo được ở thời điểm bị Delay như sau:
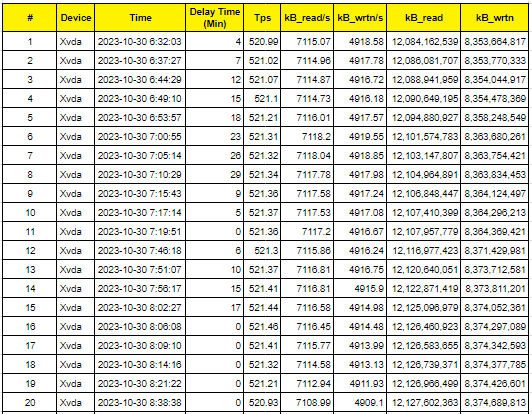
Theo dữ liệu này thì tốc độ đọc ghi Storage bình thường, không vấn đề gì. Từ lượng dữ liệu đọc ghi được và thời gian tôi tính toán thêm dữ liệu:
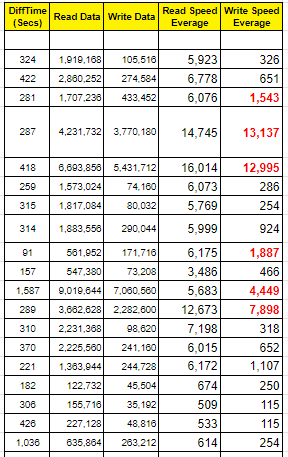
Qua dữ liệu thống kê ở trên, ở thời điểm bị trễ, lượng dữ liệu ghi rất nhiều, thể hiện qua thông số “Write Speed Everage” cao. Như vậy, nguyên nhân trễ là do trong một số thời điểm, lượng data cần ghi vào Storage nhiều, nhiều hơn khả năng đáp ứng của Storage. Lượng data sinh ra nhiều hay ít phụ thuộc vào giao dịch, có giao dịch sinh ra nhiều dữ liệu, có giao dịch sinh ra ít dữ liệu, việc này hoàn toàn ngẫu nhiên phụ thuộc vào giao dịch.
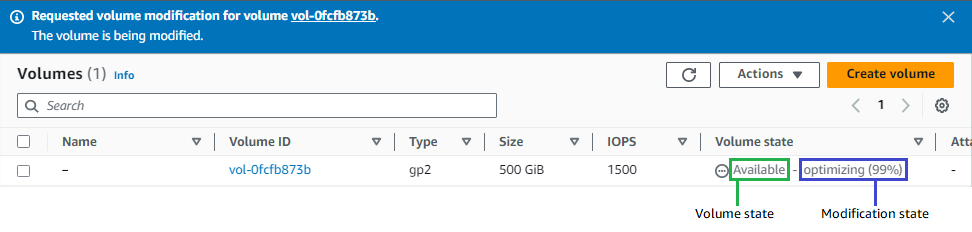
Giải pháp: Chuyển Storage từ GP2 sang GP3, với GP3 để các thông số IOPS, Throughput lên tối đa. Có thể phải mất đến 24h để ăn thông số mới, xem thêm: Migrate your Amazon EBS volumes from gp2 to gp3 and save up to 20% on costs. Xem quá trình cập nhật thay đổi tại: Monitor the progress of volume modifications
Base Node liên tục chậm 10h
Gần đây, ngày 2024-01-11, tự nhiện Node bị chậm, mà điều lạ là luôn chậm ở khoảng 12h (Khoảng 725 phút đến 726 phút). Đến đoạn này thì tốc độ Sync bằng tốc độ chậm. Mình thấy có Issue tương tự trên github Issue 127: node consistently 12 hours behind
Thử rất nhiều cách khác nhau và may mắn đã có cách thành công:
- Tăng IOPS, Throughput của GP3 lên tối đa => Vẫn không được, node vẫn chậm khoảng 12h
- Tăng Storage lên để tăng tỉ lệ trống => Vẫn bị chậm 12h
- Đổi sang Instance Type với cấu hình cao hơn gấp đôi => Vẫn bị chậm 12h
- Cập nhật phiên bản mới (Cũ dùng v0.3.1, chuyển sang bản mới v0.6.1) những vẫn dùng dữ liệu cũ => Thấy log báo “Walking back L1Block by hash” liên tục, sau 2 ngày vẫn báo và chưa thấy thực hiện đồng bộ. Có thể bản mới đã thay đổi dữ liệu lưu => Xem tại Issue 104: Walking back L1Block by hash
- Tạo server mới, sử dụng bản mới v0.6.1 và bản snapshot mới nhất (Được chụp trước đó 7 ngày) => Ban đầu trễ 7 ngày, nhưng tốc độ đồng bộ khá nhanh, sau 1 ngày, độ trễ giảm về 39h => Tầm 1.5 ngày thì hoàn thành đồng bộ
Để tìm hiểu nguyên nhân thực sự của vấn đề này, mình đã rà soát lại các bản nâng cấp gần đây trong Base Node Tags. Rà soát các notes của từng tag thì thấy:
- v0.6.0: Bắt buộc phải cập nhật trước 2024-01-10 vì nó gồm tất cả các tính năng cần thiết cho hardfork Mainnet Canyon sẽ được kích hoạt lúc 17:00:01 UTC ngày 2024-01-11. Khi kiểm tra thông báo lỗi của Node mất đồng bộ bắt đầu lúc 00:01:00 VN ngày 2024-01-12, khớp thời gian luôn.
Thời điểm trùng khớp luôn, như vậy do mình không nâng cấp node trước thời điểm này, thành ra mới gặp vấn đề như vậy.
Độ trễ khá cao khi đồng bộ các block
Tôi đã viết code nhỏ trên chính Base Node, thực hiện subcribe để lấy dữ liệu block qua WebSocket. Tôi đo hiệu thời gian: <Thời gian nhận được dữ liệu – ReceivedTime> – <Thời gian sinh ra block – BlockTime>, tôi gọi là thời gian trễ DelayTime. Chúng ta cần DelayTime này càng nhỏ càng tốt, dưới 600ms là tốt nhất.
Theo dữ liệu đo được trong vòng gần 3 ngày với khoảng 116490 block thì:
- Chỉ có chưa đến 5% các block có DelayTime<=600ms
- 17% block có DelayTime<=1000ms

Cuộc chiến trên Dex đòi hỏi tốc độ, vì thế DelayTime là bài toán cực lớn. Mặc dù đã tăng thông số cho EBS gp3 lên mức tối đa (Throughput=1000 và IOPS=16000) nhưng kết quả không được cải thiện.
Sau khi tìm kiếm trên Google, trong bài Do different EC2 instance types have different EBS I/O performance characteristics?, một bạn nói rằng: “EBS là một tài nguyên được chia sẻ. Hiệu suất của nó sẽ thay đổi tùy theo số lượng người bạn đang chia sẻ nó và những gì mọi người đang làm với nó.”.

Như vậy ta chọn được EBS càng chia sẻ ít người thì càng tốt. Thực tế EBS sẽ không bao giờ đạt được thông lượng như mong muốn. Chúng ta có thể đo bằng cách tạo shell disk-benchmark.sh như sau:
#!/bin/bash
# Install sysbench
#sudo apt install sysbench
currTime=$(date '+%Y-%m-%d %H:%M:%S')
echo "Start time: $currTime"
echo ""
sysbench --file-total-size=15G --file-num=16 fileio prepare
sysbench --file-total-size=15G --file-num=16 --file-test-mode=rndrw --time=600 fileio run
sysbench --file-total-size=15G --file-num=16 fileio cleanup
echo ""
currTime=$(date '+%Y-%m-%d %H:%M:%S')
echo "End time: $currTime"Sau đó chạy bằng lệnh sau:
chmod +x disk-benchmark.sh
./disk-benchmark.shNhư vậy chúng ta sẽ có 2 lựa chọn để cải thiện hiệu năng truy cập EBS:
- Location: Lựa chọn vị trí mà ít người sử dụng hoặc ít người chạy Node hơn.
- Instance Type: Ta chọn Instance Type lớn hơn, bởi chi phí đắt hơn thì ít người dùng hơn.
Sau một thời gian sử dụng và cài đặt nhiều lần thì bạn nâng Instance Type càng cao thì tốc độ càng tốt hơn. Nhưng với một mức giá rẻ hơn, cấu hình cao hơn nhiều, tốc độ đồng bộ nhanh hơn thì Hetzner là lựa chọn tốt nhất.
Lỗi: failed to check L1 Beacon API version
Ngày 2024-02-26, hệ thống Base Node bị mất đồng bộ thời gian khá lâu, khi kiểm tra mới biết Base Node đã nâng cấp phiên bản mới. Trước dùng phiên bản v0.6.1, hiện tại đã lên phiên bản v0.8.0, trong đó quan trọng nhất là phiên bản v0.7.0 yêu cầu phải cập nhật trước ngày 2024-02-22.
Sau khi nâng cấp phiên bản, cập nhật cấu hình và thiết lập OP_NODE_L1_BEACON chính là Ethereum RPC luôn nhưng không được, chạy báo lỗi:
basenode-v061-geth-1 | INFO [02-29|02:54:33.493] Generating state snapshot root=97a50d..8aa067 in=033975..3d0046 at=000628..dd6abf accounts=758,174 slots=565,944 storage=92.78MiB dangling=0 elapsed=16.006s eta=6h40m10.367s
basenode-v061-node-1 | t=2024-02-29T02:54:34+0000 lvl=eror msg="Error initializing the rollup node" err="failed to check L1 Beacon API version: operation failed permanently after 5 attempts: failed request with status 404: not found"
basenode-v061-node-1 | t=2024-02-29T02:54:34+0000 lvl=crit msg="Application failed" message="failed to setup: unable to create the rollup node: failed to check L1 Beacon API version: operation failed permanently after 5 attempts: failed request with status 404: not found"
basenode-v061-node-1 exited with code 1Như vậy trong phiên bản mới, bắt buộc phải cập nhật cấu hình OP_NODE_L1_BEACON bằng Beacon API. Mà API này không có public như RPC. Tôi phải mua trên https://www.ankr.com/rpc/eth/ (Chọn Beacon => Upgrade Now). Sau khi cập nhật xong Beacon API thì Base Node lại chạy bình thường.
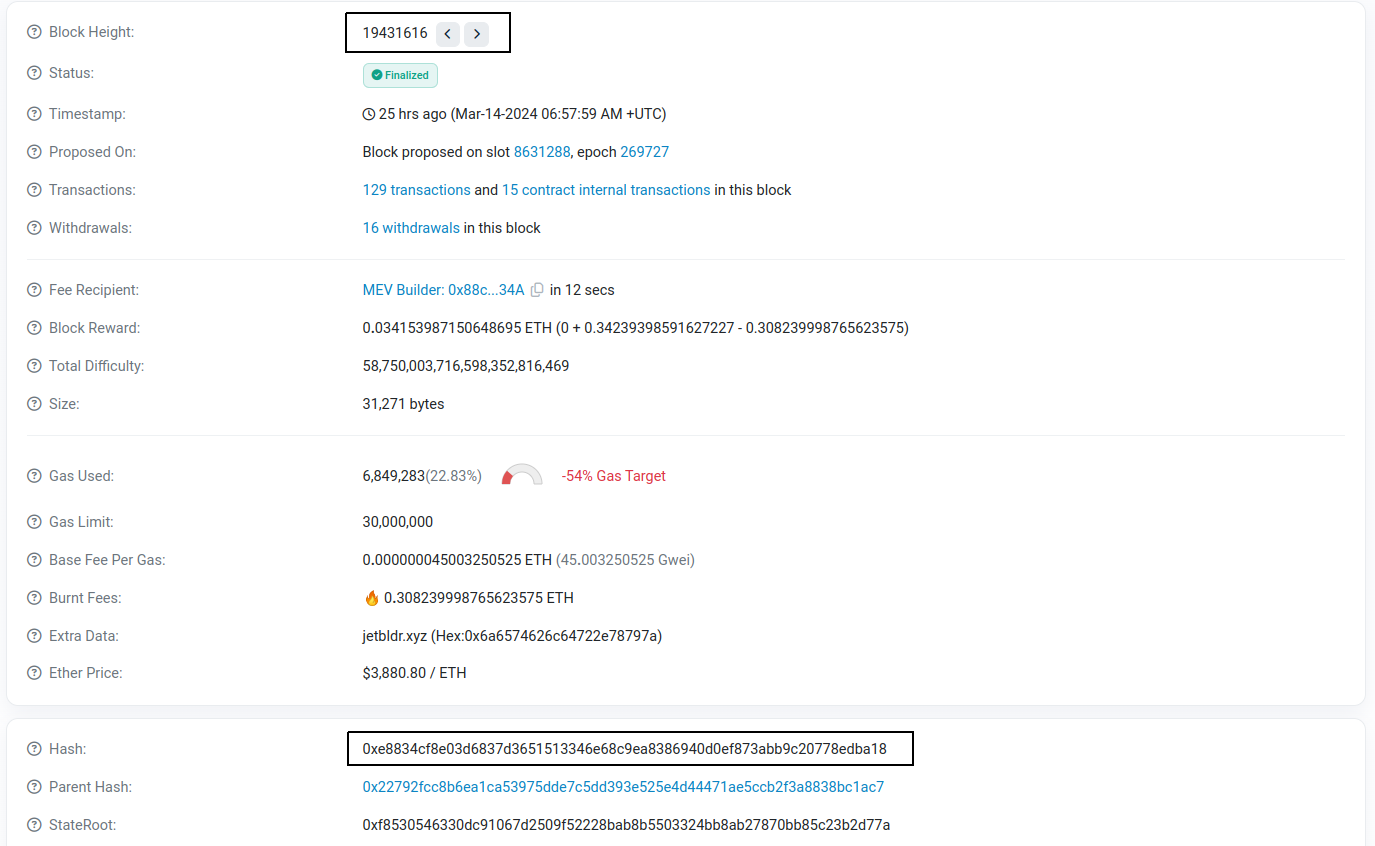
Lỗi: Base Node dừng đồng bộ ở block 19431616
Sáng ngày 2024-03-15, Base Node tiếp tục gặp vấn đề không thể đồng bộ được. Thực hiện chạy đi chạy lại nhiều lần không được, mỗi lần bắt đầu chạy thì Base Node sẽ check ở block mới nhất trên L1, sau đó đi ngược lại như log sau:
node-1 | t=2024-03-15T05:20:32+0000 lvl=info msg="Walking back L1Block by hash" curr=0x64dcd84b40e9883a8d229325b1bc14c5a198e62f7ca60775cf41bd53cfc9e948:19436382 next=0x2950ca2c208b54d834391573e282702f9b3b61116cf7e23bfbdfab89cc4ec9b8:19436381 l2block=0x10bd1c8061ec954d9811362a1317db092c5031bf68dc6094ee2283146fa8590e:11834226
node-1 | t=2024-03-15T05:20:32+0000 lvl=info msg="Walking back L1Block by hash" curr=0x2950ca2c208b54d834391573e282702f9b3b61116cf7e23bfbdfab89cc4ec9b8:19436381 next=0x33c3dbea193d9cbb765d8bb0fb4f3a107bd4f043640ce0b6c436c50f6e179aa9:19436380 l2block=0xd19f216a046bfcfa16dd3577928b3330f7f73e90dfb0479ed713772963db6e4c:11834220
node-1 | t=2024-03-15T05:20:32+0000 lvl=info msg="Walking back L1Block by hash" curr=0x33c3dbea193d9cbb765d8bb0fb4f3a107bd4f043640ce0b6c436c50f6e179aa9:19436380 next=0x3d07f97ab789431303e2260c21cfc6e39728ae7d3e96bf2f6f928344a9fa8a15:19436379 l2block=0x93bca5feed880a1902aee7e73686870647395f5885d6837830f89b81679ad9b9:11834214
node-1 | t=2024-03-15T05:20:33+0000 lvl=info msg="Walking back L1Block by hash" curr=0x3d07f97ab789431303e2260c21cfc6e39728ae7d3e96bf2f6f928344a9fa8a15:19436379 next=0x271c01fb91c596de7f90c503b683df8da09b88422f6dd66297b7b07c5885aa1a:19436378 l2block=0x3976e5b4ad9038f6a113c45da4dfc2530fce641697e8abb274965655158b38d5:11834208Nhưng điều lạ là cứ về đến block 19431616 thì gặp vấn đề và Base Node lại lấy thông tin từ L1 lại từ đầu:
Line 9245: node-1 | t=2024-03-15T05:19:14+0000 lvl=warn msg="Derivation process temporary error" attempts=22 err="temp: failed to fetch receipts of L1 block 0xac8f46a2bfbd742167d9591a866c9a6410b36bc7de9fa45845d8f3ace3b3e5aa:19431616 (parent: 0x22792fcc8b6ea1ca53975dde7c5dd393e525e4d44471ae5ccb2f3a8838bc1ac7:19431615) for L1 sysCfg update: block ac8f46a2bfbd742167d9591a866c9a6410b36bc7de9fa45845d8f3ace3b3e5aa not found"
Line 9313: node-1 | t=2024-03-15T05:19:24+0000 lvl=warn msg="Derivation process temporary error" attempts=23 err="temp: failed to fetch receipts of L1 block 0xac8f46a2bfbd742167d9591a866c9a6410b36bc7de9fa45845d8f3ace3b3e5aa:19431616 (parent: 0x22792fcc8b6ea1ca53975dde7c5dd393e525e4d44471ae5ccb2f3a8838bc1ac7:19431615) for L1 sysCfg update: block ac8f46a2bfbd742167d9591a866c9a6410b36bc7de9fa45845d8f3ace3b3e5aa not found"
Line 9384: node-1 | t=2024-03-15T05:19:34+0000 lvl=warn msg="Derivation process temporary error" attempts=24 err="temp: failed to fetch receipts of L1 block 0xac8f46a2bfbd742167d9591a866c9a6410b36bc7de9fa45845d8f3ace3b3e5aa:19431616 (parent: 0x22792fcc8b6ea1ca53975dde7c5dd393e525e4d44471ae5ccb2f3a8838bc1ac7:19431615) for L1 sysCfg update: block ac8f46a2bfbd742167d9591a866c9a6410b36bc7de9fa45845d8f3ace3b3e5aa not found"Dựa trên thông tin log thu được thì ở block 19431616 ứng với hash là 0xac8f46a2bfbd742167d9591a866c9a6410b36bc7de9fa45845d8f3ace3b3e5aa nhưng kiểm tra trên Etherscan thì thấy dữ liệu Block Hash không khớp:
Kiểm tra lại nâng cấp Dencun gần đây thì thấy xảy ra ở epoch 269568, beacon slot 8626176, tương ứng với block 19424209, trước block 19431616 khá nhiều. Như vậy không liên quan tới nâng cấp Dencun.
Kiểm tra các Forked Block của Ethereum gần đây thì thấy có hiện tượng fork xảy ra ở block này:
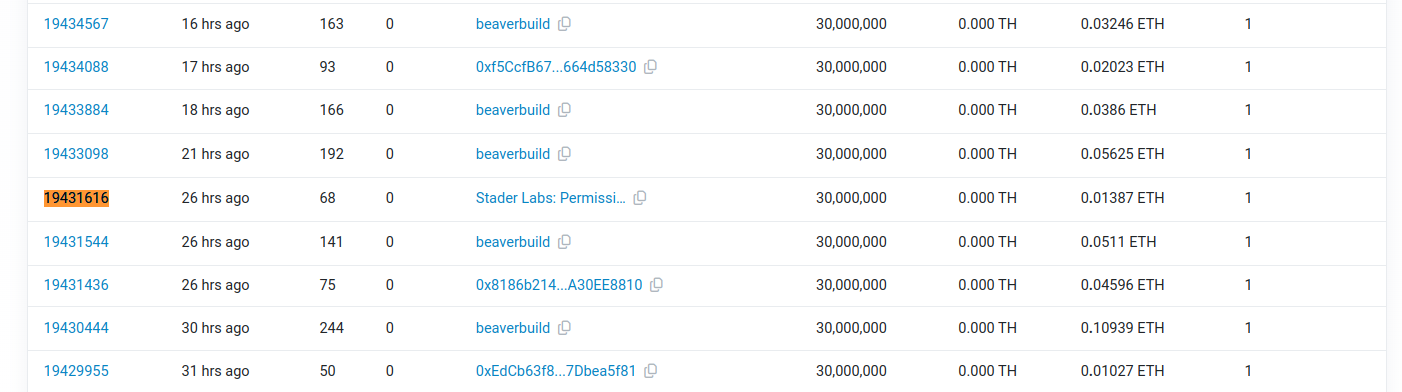
Như vậy vấn đề nằm ở L1, mà tôi đang sử dụng RPC của Ankr, như vậy Node của Ankr gặp vấn đề ở block 19431616. Tôi đã chuyển sang rpc của Alchemy thì quá trình đồng bộ OKIE. Dĩ nhiên với Alchemy bạn phải nâng cấp thì mới chạy được, không thì sẽ gặp lỗi “Too many requests“.
Lỗi: Thời gian nhận block trước cả thời gian sinh ra block
Khi viết đoạn code nhỏ bắt sự kiện lấy thông tin block mới và tiến hành đo thời gian từ thời điểm nhận được block mới với timestamp của block thì nhận thấy gía trị này hầu như âm, tức là nhận sự kiện trước cả sinh block. Điều này rất vô lý:
12452524,1711694395,1711694394030,-970
12452525,1711694397,1711694396264,-736
12452526,1711694399,1711694398129,-871
12452527,1711694401,1711694400148,-852
12452528,1711694403,1711694402284,-716
12452529,1711694405,1711694403986,-1014
12452530,1711694407,1711694406497,-503
12452531,1711694409,1711694408426,-574
12452532,1711694411,1711694410538,-462
12452533,1711694413,1711694411996,-1004Sau khi kiểm tra thấy thời gian OS đang không được đồng bộ:
timedatectl
------------------------------------------
Local time: Fri 2024-03-29 04:58:05 UTC
Universal time: Fri 2024-03-29 04:58:05 UTC
RTC time: Fri 2024-03-29 04:58:18
Time zone: Etc/UTC (UTC, +0000)
System clock synchronized: no
NTP service: active
RTC in local TZ: noTrường “System clock synchronized” là no, chứng tỏ không đồng bộ. Ngoài ra thời gian “Universal time” và “RTC time” đang lệch nhau 13s. Tôi sử dụng lệnh sau để fix:
# Chuyển timezone về đúng nơi đặt server
timedatectl set-timezone Europe/Berlin
# Là lệnh kép gồm 2 lệnh đơn
# Lệnh 1: Đồng bộ thời gian hệ thống sử dụng ntpupdate
# Lệnh 2: Đồng bộ thời gian cảu hardward với thời gian hệ thống
ntpdate 0.ubuntu.pool.ntp.org ; hwclock --systohc
# Kiểm tra lại thời gian
timedatectl
-----------------------------
Local time: Fri 2024-03-29 08:21:49 CET
Universal time: Fri 2024-03-29 07:21:49 UTC
RTC time: Fri 2024-03-29 07:21:49
Time zone: Europe/Berlin (CET, +0100)
System clock synchronized: no
NTP service: active
RTC in local TZ: noThời gian đã khớp nhưng “System clock synchronized” là no, chứng tỏ thời gian chưa đồng bộ.
Mặc định Ubuntu hệ thống chạy dịch vụ systemd-timesyncd để đồng bộ thời gian. Nếu chưa có thì có thể cài đặt và chạy bằng lệnh:
sudo apt install systemd-timesyncd
systemctl enable --now systemd-timesyncd
service systemd-timesyncd startKhi kiểm tra log dịch vụ này thì thấy báo lỗi timeout do không kết nối được ntp time server:
service systemd-timesyncd status
● systemd-timesyncd.service - Network Time Synchronization
Loaded: loaded (/lib/systemd/system/systemd-timesyncd.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2024-03-29 07:28:05 CET; 2h 31min ago
Docs: man:systemd-timesyncd.service(8)
Main PID: 207745 (systemd-timesyn)
Status: "Idle."
Tasks: 2 (limit: 154029)
Memory: 1.3M
CPU: 141ms
CGroup: /system.slice/systemd-timesyncd.service
└─207745 /lib/systemd/systemd-timesyncd
Mar 29 09:18:44 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from [2a01:4f8:0:a112::2:2]:123 (ntp2.hetzner.com).
Mar 29 09:18:54 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from 213.239.239.165:123 (ntp2.hetzner.com).
Mar 29 09:19:04 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from [2a01:4f8:0:a101::2:3]:123 (ntp3.hetzner.net).
Mar 29 09:19:15 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from 213.239.239.166:123 (ntp3.hetzner.net).
Mar 29 09:53:33 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from [2a01:4f8:0:a0a1::2:1]:123 (ntp1.hetzner.de).
Mar 29 09:53:43 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from 213.239.239.164:123 (ntp1.hetzner.de).
Mar 29 09:53:54 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from [2a01:4f8:0:a112::2:2]:123 (ntp2.hetzner.com).
Mar 29 09:54:04 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from 213.239.239.165:123 (ntp2.hetzner.com).
Mar 29 09:54:14 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from [2a01:4f8:0:a101::2:3]:123 (ntp3.hetzner.net).
Mar 29 09:54:24 Ubuntu-2204-jammy-amd64-base systemd-timesyncd[207745]: Timed out waiting for reply from 213.239.239.166:123 (ntp3.hetzner.net).Dùng ntpdate ở chế độ debug để kiểm tra:
# Cài đặt ntpdate
apt install ntpdate
# Kiểm tra
ntpdate -d ntp2.hetzner.com
---------------
29 Mar 09:55:54 ntpdate[208389]: ntpdate 4.2.8p15@1.3728-o Wed Feb 16 17:13:02 UTC 2022 (1)
Looking for host ntp2.hetzner.com and service ntp
2a01:4f8:0:a112::2:2 reversed to ntp2.hetzner.de
host found : ntp2.hetzner.de
transmit(2a01:4f8:0:a112::2:2)
transmit(213.239.239.165)
transmit(2a01:4f8:0:a112::2:2)
transmit(213.239.239.165)
transmit(2a01:4f8:0:a112::2:2)
transmit(213.239.239.165)
transmit(2a01:4f8:0:a112::2:2)
transmit(213.239.239.165)
2a01:4f8:0:a112::2:2: Server dropped: no data
213.239.239.165: Server dropped: no data
29 Mar 09:56:02 ntpdate[208389]: no server suitable for synchronization foundHóa ra vấn đề do kết nối, trong phần “Rules (incoming)“, phải mở thêm kết nối port 123.

Sau đó restart lại dịch vụ là okie:
# Restart lại dịch vụ
service systemd-timesyncd restart
# Kiểm tra lại trạng thái
timedatectl
-----------------------------
Local time: Fri 2024-03-29 10:10:20 CET
Universal time: Fri 2024-03-29 09:10:20 UTC
RTC time: Fri 2024-03-29 09:10:20
Time zone: Europe/Berlin (CET, +0100)
System clock synchronized: yes
NTP service: active
RTC in local TZ: noLỗi: Thời gian nhận sự kiện newBlock chậm 2s đến 3s so với thời điểm sinh block
Lỗi này do tôi sử dụng lại RPC của Ankr để tiết kiệm chi phí, sau đó đến block 19698170 thì bị lỗi, Ankr trả về thông tin hash không khớp với trên Etherscan. Ở block 19698170, thì Ankr trả về block hash là 0x19742348e32f2c5962266331939193915f4c9efd587f257f440112eb8fc3e9b6 nhưng trên etherscan thì block hash là 0xf7189b21541baa2726409965ae6b5df3e52cb856fa9b52b1a1bccb209d5625da.
Do bị lỗi ở block 19698170 nên thực tế “Finalized Block” là 19698119. Mặc dù bị lỗi L1 nhưng hệ thống vẫn đồng bộ được từ các P2P khác, chỉ là các block đồng bộ từ P2P sẽ không phải là Finalized Block, do đó hệ thống cần kiểm tra từ “Finalized Block” tới block hiện tại, do đó tốn thời gian hơn. Do cấu hình server mạnh nên quá trình này chỉ mất 1s đến 2s, nếu cấu hình server thấp quá trình này có thể mất đến vài phút và càng ngày càng tăng theo thời gian do khoảng cách từ block hiện tại tới “Finalized Block” càng xa.
Giải pháp đơn giản chỉ là đổi sang L1 RPC khác và restart lại node.
Giảm dung lượng Storage
Có một khoảng thời gian dung lượng Storage tăng rất nhanh, khoảng 100G/ngày, sau đó dung lượng đạt tới 2.5T trên tổng 2.9T. Sau đó do một lần Fullnode gặp vấn đề, tôi phải restart lại EC2 thì tự nhiên dung lượng sử dụng chỉ còn 1.6T. Tự nhiên dung lượng thừa đến 1.3T rất lãng phí (tương đương 130$/tháng). Tôi cần giảm dung lượng này để giảm chi phí.
Có nhiều cách giảm dung lượng, bạn xem bài viết: Hướng dẫn giảm kích thước EBS Storage trong EC2. Có 2 cách:
- C1: Dựng lại node mới, thực hiện cơ chế về tải về vừa giải nén để đảm bảo dung lượng => Chi phí tải về, giải nén và đồng bộ tiếp mất khá nhiều thời gian. Bạn có thể sử dụng lệnh sau:
wget -qO- https://base-mainnet-archive-snapshots.s3.us-east-1.amazonaws.com/$(curl https://base-mainnet-archive-snapshots.s3.us-east-1.amazonaws.com/latest) | tar xvz - C2: Tạo EC2 mới với volume mong muốn và thực hiện đồng bộ thư mục cần qua rsync =>Tôi chọn giải pháp này
Một số lệnh hay dùng để đo Storage
Vấn đề liên quan đến Storage thường là vấn đề chính hay gặp trên Node Base. Cần nắm một số lệnh để đo các thông số liên quan tới Storage:
// Xem thông tin các phân vùng
sudo lsblk
// Xem dung lượng
df -h
df -hT
// Đo thời gian đọc
sudo hdparm -Tt /dev/xvda1
// Đo tốc độ ghi file
dd if=/dev/zero of=/tmp/tempfile bs=1M count=1024
// Đo tốc độ đọc file
dd if=/dev/zero of=/dev/null bs=1M count=1024Hướng dẫn build source code của Base node
Source code chính của Base node chủ yếu trong op-geth và op-node
Hướng dẫn build mã nguồn của op-geth
Để build source code của op-geth ta thực hiện các lệnh sau (Tham khảo thêm: Building the source):
# Cài đặt Go 1.19.13 chuẩn nhất (Cài 1.21 thì build được op-geth nhưng không build được op-node)
# https://go.dev/doc/install
sudo -i
rm -rf /usr/local/go
wget https://go.dev/dl/go1.19.13.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.19.13.linux-amd64.tar.gz
rm go1.19.13.linux-amd64.tar.gz
exit
# Cài đặt các công cụ hỗ trợ build code
sudo apt-get install build-essential
# Tải mã nguồn của op-eth
git clone https://github.com/base-org/op-geth.git
mv op-geth base-op-geth
cd base-op-geth
git checkout v1.101105.1
# Trước khi build cần thêm thư mục Go vào biến môi trường PATH
export PATH=$PATH:/usr/local/go/bin
# Thực hiện build all để có được nhiều công cụ hơn
# Nếu bạn chỉ muốn build geth thì dùng lệnh: make geth
make all
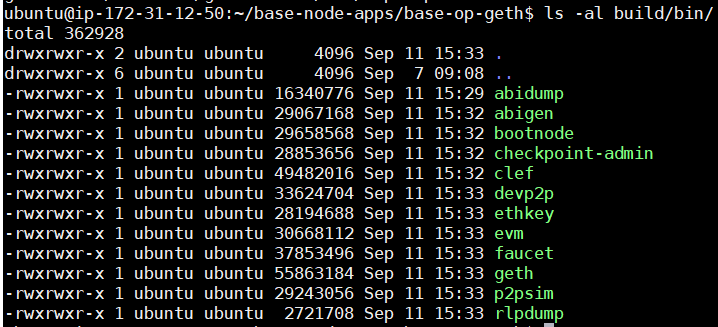
# Sau build xong se thay tep trong thu muc build/bin/
ls Thời gian build khá nhanh, mất 3 phút là cùng. Sau khi build xong, các tệp thực thi trong thư mục build/bin/
Hướng dẫn build mã nguồn của op-node
Để build source code của op-node (rollup consensus-layer client) ta thực hiện các lệnh sau (Tham khảo thêm: Compiling):
# Cài đặt Go
# Đã cài đặt khi build op-geth
# Nên không cần cài đặt lại
# Tải mã nguồn về
git clone https://github.com/ethereum-optimism/optimism.git
mv optimism base-optimism
cd base-optimism
git checkout v1.1.4
# Trước khi build cần thêm thư mục Go vào biến môi trường PATH
export PATH=$PATH:/usr/local/go/bin
# Build mã nguồn
cd op-node
go build -o bin/op-node ./cmdNếu bạn muốn build optimism thì xem tệp: Optimism monorepo contributing guide
Một số lỗi phát sinh khi build mã nguồn
Lỗi build op-node: “The version of quic-go you’re using can’t be built on Go 1.21 yet”
Khi build op-node, chạy một lúc thì báo lỗi sau:
# github.com/quic-go/quic-go/internal/qtls
../../../go/pkg/mod/github.com/quic-go/quic-go@v0.33.0/internal/qtls/go121.go:5:13: cannot use "The version of quic-go you're using can't be built on Go 1.21 yet. For more details, please see https://github.com/quic-go/quic-go/wiki/quic-go-and-Go-versions." (untyped string constant "The version of quic-go you're using can't be built on Go 1.21 yet. F...) as int value in variable declarationLỗi này do mình cài bản go v1.21 nên không build được thư viện quic-go v0.33.0 => Mình chuyển về cài bản go v1.19.13 thì build OK. Kết quả sau khi build có tệp op-node trong thư mục bin:

Một số thao tác với Fullnode
Sau khi đã cài Fullnode và đồng bộ okie. Chúng ta tìm hiểu thêm một số vấn đề.
Làm sao sử dụng Geth Console?
Bạn có thể tương tác với Fullnode qua RPC, nhưng cách đơn giản nhất là tương tác với Fullnode qua “Geth Console“. Nhưng do chúng ta chạy sử dụng docker nên chúng ta không có tệp thực thi geth, vì thế đầu tiên chúng ta cần lấy tệp geth trước đã:
// Dùng lệnh sau để xem các container đang chạy
// Chúng ta lấy được Container ID của thằng chạy lệnh geth-entrypoint => Giả sử: 4ffa69583e72
sudo docker ps
// Chúng ta xem có tệp geth trong container hay không?
// Bạn sẽ nhìn thấy geth
sudo docker exec 4ffa69583e72 ls -al
// Xem geth đang ở thư mục nào
// Bạn sẽ nhìn thấy thư mục: /app
sudo docker exec 4ffa69583e72 pwd
// Tạo thự mục chứa tệp thực thi cho node
mkdir base-node-apps
cd base-node-apps
// Copy tệp geth từ container ra ngoài
sudo docker cp 4ffa69583e72:/app/geth .
Bây giờ, khi đã có tệp thực thi geth thì ta chạy lệnh sau để vào chế độ console:
// Vào chế độ console của Geth
// Tham khảo: https://geth.ethereum.org/docs/getting-started
./geth attach http://127.0.0.1:8545
// Thử một số lệnh trong namespace: eth
eth.accounts
eth.blockNumber
eth.chainId()
Nếu không có thể chạy trực tiếp trên container:
# Vào container để chay
sudo docker exec -it 4ffa69583e72 bash
# Chạy lệnh geth console
./geth attach http://127.0.0.1:8545Chi tiết lệnh xem:
- Namespace: eth => Chứa các hàm cơ bản thao tác với Node
- Namespace: net => Cung cấp thông tin về các client kết nối tới Node
- Namespace: txpool => Cung cấp thông tin về transaction pool
- Namespace: debug => Cung cấp thông tin giúp dev gỡ lỗi ứng dụng
- Namespace:admin => Cung cấp các thông tin liên quan tới các peers (Các remote node)
Làm sao biết được Fullnode hiện tại đang kết nối tới những node nào?
Theo tìm hiểu trong “Geth Console” có hàm admin_peers trong namespace admin để hiện thị các thằng mà node đang kết nối đến. Nhưng để dùng được hàm này thì khi chạy node phải bật namespace admin này lên trong cấu hình –http.api. Ví dụ:
--http.api debug,eth,web3,personal,net,adminNhư vậy chúng ta phải sửa tệp geth-entrypoint ở dòng:
–http.api=web3,debug,eth,txpool,net,engine
đổi sang:
–http.api=web3,debug,eth,txpool,net,engine,admin
Sau đó vào Geth Console, đánh lệnh admin.peers nhưng lại báo lỗi:
> admin.peers
ReferenceError: admin is not defined
at <eval>:1:1(0)Thử tiếp với RPC và vẫn bị lỗi:
curl --data '{"method":"admin_peers","params":[],"id":1,"jsonrpc":"2.0"}' -H "Content-Type: application/json" -X POST http://localhost:8545
{"jsonrpc":"2.0","id":1,"error":{"code":-32601,"message":"the method admin_peers does not exist/is not available"}}Chứng tỏ geth trên Base đã sửa đổi và không hỗ trợ. Cần tìm hiểu thêm op-geth, nếu muốn biết chi tiết peer cần sửa thêm log vào op-geth.
Đơn giản chỉ cần biết nhận dữ liệu nào thì ta có thể làm theo hướng dẫn dưới.
Trích suất log các peer để biết node nhận dữ liệu từ node nào?
Log của Fullnode cũng hiển thị khá chi tiết về thông tin các peer nhưng cần phải tổng hợp lại mới có dữ liệu đầy đủ.
Qua tìm hiểu và xem các log thì thấy log liên quan tới Peer sẽ chứa các message sau:
- “attempting connection” => Log này thông báo đang cố gắng connect tới một Peer. Trong log có chứa PeerId.
base-node-node-1 | t=2023-09-08T03:28:26+0000 lvl=info msg=”attempting connection” peer=16Uiu2HAm79zXtoZ8nb9gSbtpT7Txxus8KCC3yagAT6zyEmdvW6ih - “connected to peer” => Log này thông báo đã kết nối tới một Peer. Trong log có chứa PeerId và IP
base-node-node-1 | t=2023-09-08T03:28:27+0000 lvl=info msg=”connected to peer” peer=16Uiu2HAm79zXtoZ8nb9gSbtpT7Txxus8KCC3yagAT6zyEmdvW6ih addr=/ip4/51.81.137.96/tcp/9222 - “disconnected from peer” => Log này thông báo mất kết nối từ một Peer. Log này chứa PeerId và IP
base-node-node-1 | t=2023-09-08T03:29:21+0000 lvl=info msg=”disconnected from peer” peer=16Uiu2HAm73QmJuj8XNviFhfnFCxDBMwTD8SmEgVcT4Y22tpypseL addr=/ip4/18.143.5.146/tcp/9222 - “Received signed execution payload from p2p” => Log này thông báo nhận dữ liệu từ 1 Peer. Log này chứa thông tin PeerId, BlockHash và BlockNumber.
base-node-node-1 | t=2023-09-08T03:28:33+0000 lvl=info msg=”Received signed execution payload from p2p” id=0x27c3a97926bed189744836685d31fa8e364d1653287eb11f7164beae1a4ace9e:3677183 peer=16Uiu2HAmDnwNhGHcnmDbak7LZcePWHLv2EZz6QJm8aiqQvy4ADQZ
Để lấy được dữ liệu log liên quan Peer, chúng ta sẽ tách log này ra bằng lệnh sau:
sudo docker compose logs | grep -E "attempting connection|connected to peer|disconnected from peer|Received signed execution payload from p2p" > base-node-peer.logSau khi có log này, chúng ta viết file bằng NodeJs để parse log này cho ta dữ liệu cần. Ảnh dưới là kết quả sau khi đã parse log:
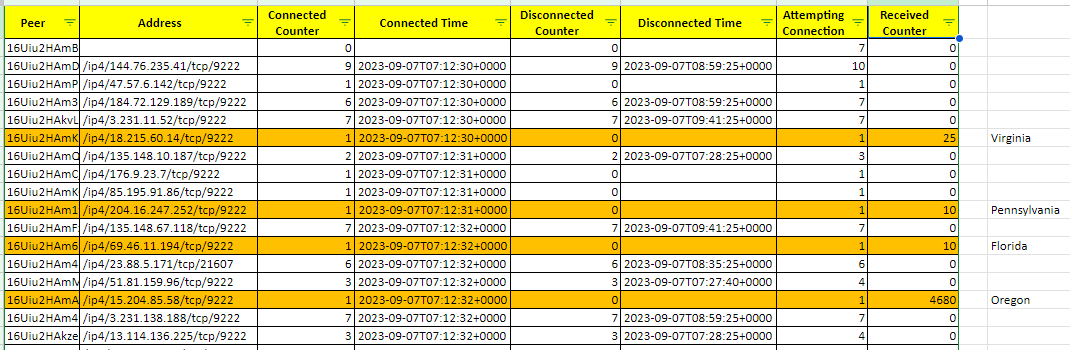
Làm sao để giảm dung lượng lưu trữ
Bắt đầu tầm 2023-10-10, sau khi để ý thấy dung lượng SSD giảm rất nhanh, kiểm tra và đo dữ liệu mới thấy mỗi ngày Node trên Base cần 100G dữ liệu để lưu trữ. Tốc độ tăng dung lượng này thực sự lớn hơn rất nhiều so với các blockchain khác.
Sau đó đã thử tìm hiểu xem có giải pháp nào giúp giảm dung lượng như:
- Nén dữ liệu cũ
- Loại bỏ dữ liệu cũ (Trong trường hợp node chỉ sử dụng dữ liệu gần đây)
- Di chuyển dữ liệu cũ sang bộ lưu trữ rẻ hơn như HDD
Nhưng đã thất vọng vì không tìm được, đành phải raise vấn đề này lên github của dự án: Need a mechanism to compress data to reduce storage costs
Tìm hiểu sâu hơn mã nguồn của Base blockchain
Thực ra mã nguồn của Base rất phức tạp, phần node chỉ là phần đóng gói để chạy node, còn mã nguồn chính nằm ở op-geth. Để có thể hiểu hết luồng thì thực sự cần rất nhiều thời gian, ở đây chúng ta chỉ tập trung tìm hiểu để giải đáp một số vấn đề.
Cơ chế của Node trên Base
Theo bài Differences between Ethereum and Base, nói Base sử dụng BedRock của Op Stack. Cách Execution Client và Rollup Node sử dụng sequencer và các node giao tiếp đồng bộ theo peer-to-peer. Và trong cấu hình của .env.mainnet cũng có các cấu hình liên quan tới P2P. Như vậy cơ chế đồng bộ trên Node của Base là thông qua cơ chế P2P.
Trong geth có tham số maxpeers đang để là 100 (Xem geth-entrypoint), còn mặc định để là 50 (Xem defaults.go, search MaxPeers thấy có nhiều chỗ có, chỗ 25 chỗ 50)
Sequencer được sử dụng để làm gì?
Trong cấu hình .env.mainnet ta thấy có cấu hình dưới liên quan tới Sequencer:
// https://github.com/base-org/node/blob/v0.3.0/.env.mainnet#L2C1-L2C58
OP_GETH_SEQUENCER_HTTP=https://mainnet-sequencer.base.orgTừ tệp docker-compose.yml, thấy node chạy cần chạy geth qua tệp geth-entrypoint, trong tệp này ta thấy sequencer được truyền vào qua tham số “rollup.sequencerhttp“.
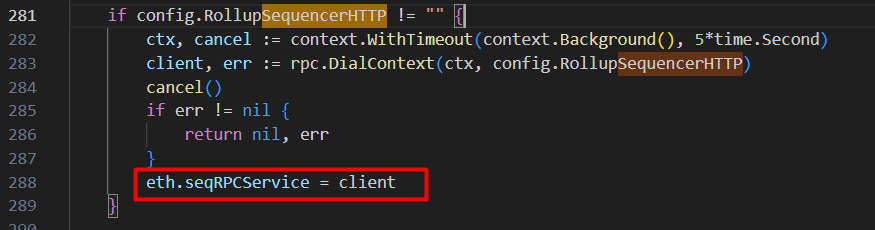
Search trong mã nguồn geth với “sequencerhttp” ta thấy nó được sử dụng để tạo ra biến eth.seqRPCService trong backend.go:
Tìm kiếm biến này trong code sẽ thấy, khi node nhận được transaction, giao dịch này sẽ được forward tới sequencer:
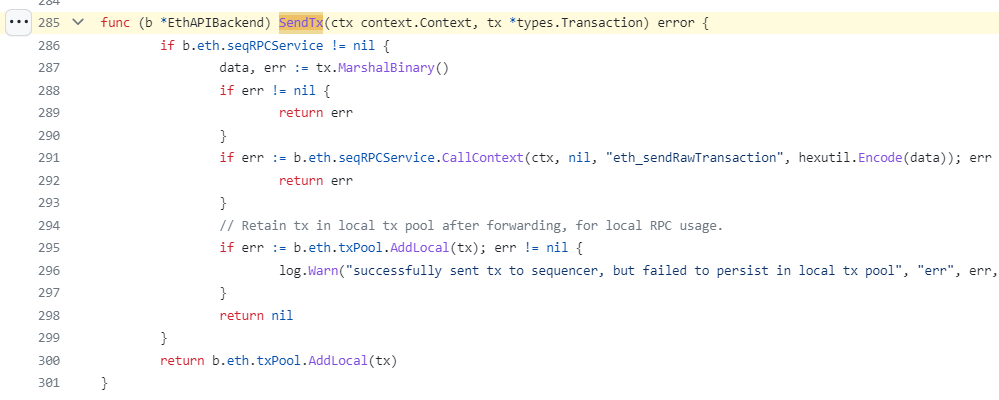
Trong code trên ta thấy, sau khi gửi giao dịch đến Sequencer, giao dịch được lưu vào MemPool của Local. Đã chạy thử code NodeJs sử dụng Websocket để nhận các pending transaction nhưng không phải block nào cũng có, lâu lâu mới có mà chỉ có 1 transaction, trong khi check block của transaction đó thì có tới 12 transaction. Như vậy chứng tỏ, mỗi Node nó chỉ chứa pending transaction của các giao dịch được gửi đến node đó chứ không phải của toàn mạng lưới.
Nguồn:

















Kevin
Đoạn sửa file .env.mainnet: “Thay giá trị cho OP_NODE_L1_ETH_RPC”
Cho mình hỏi nếu không có “Ethereum L1 full node RPC” thì set sao nhỉ, hiện thời mặc định của nó là OP_NODE_L1_ETH_RPC=https://1rpc.io/eth
Tham số này ảnh hưởng đến gì nhỉ?
Lập Trình Blockchain
Tham số này phải set bạn nhé. Nếu không có thì để mặc định của nó:
https://1rpc.io/eth
Qua một thời gian làm việc mình thấy dùng của Ankr là okie nhất. Bạn nên tạo tài khoản trên https://www.ankr.com/rpc/dashboard để lấy RPC, dùng miễn phí cũng okie rùi.
Kevin
à mình còn thắc mắc, việc chạy 1 Node có lợi gì cho người chạy Node ta (tài nguyên bỏ ra nhiều)
Lập Trình Blockchain
Trước đây mình cũng có câu hỏi như bạn, và cũng có nhiều người có cùng câu hỏi này. Sau thời gian tìm hiểu, theo hiểu biết của cá nhân mình, có một số lý do để chạy Node như sau (Thực ra còn nhiều lý do khác mình cũng không biết hết được). Một số lý do mà nhiều bên vẫn thực hiện chạy Node mặc dù chi phí khá lớn: