
Mạng lớp 2 (L2) chia sẻ bảo mật với mạng chính bằng cách xuất bản dữ liệu giao dịch trên Lớp 1 (L1). Do đó, người dùng L2 vẫn phải trả một số chi phí gas L1 khi thực hiện giao dịch. Vì Gas L1 có thể đắt hơn >25.000 lần so với Gas L2 nên việc thanh toán cho dữ liệu cuộc gọi L1 sẽ chi phối chi phí giao dịch L2. Với các hợp đồng tùy chỉnh sử dụng ít dữ liệu cuộc gọi hơn các phương pháp tiêu chuẩn, chúng ta có thể giảm đáng kể chi phí giao dịch cho người dùng.
Mục lục
Vấn đề phí Gas trên L1
Mặc dù nhiều L2 được sinh ra để giúp giảm chi phí cho một giao dịch, nhưng thực tế hiện tại, phí Gas trên L2 vẫn còn khá cao so với kỳ vọng của nhiều người:

Như ảnh trên cho thấy phí Gas trên L2 (Arbitrum, Optimism) vẫn còn khá cao so với các nền tảng khác như Solana, Polygon, Near. Vậy điều gì đang làm phí Gas trên L2 cao như vậy?
Để làm rõ được vấn đề này, chúng ta phải hiểu phí gas của một giao dịch sẽ tổng hợp từ nhiều phí nhỏ hơn:
- Phí Execution: Đây là chi phí cần thiết để tất cả các nút trong mạng thực hiện giao dịch và xác thực rằng kết quả là hợp lệ.
- Phí Storage/State: Đây là chi phí để cập nhật “cơ sở dữ liệu” của blockchain với các giá trị mới.
- Phí “Data availability“:
- Để đảm bảo blockchain không bị tin cậy và có thể được kiểm chứng bởi tất cả mọi người, blockchain phải đảm bảo rằng tất cả dữ liệu liên quan về giao dịch được chia sẻ công khai với tất cả những người tham gia mạng.
- Các L2 hiện tại đang đánh đổi “Data Availability” bằng cách chuyển thực thi sang lớp L2, sau đó lấy “Bản tổng hợp dữ liệu” đẩy lên L1 (Ethereum). Như vậy các bản tổng hợp trả phí L2 cho việc thực thi và lưu trữ, nhưng vẫn phải trả phí L1 để đăng dữ liệu của họ lên L1.
- Bạn có thể nhìn thấy phí trên L1 năng thông qua tab “Advanced TxInfo” của ArbiScan. Và trong hầu hết tất cả các giao dịch, dữ liệu cuộc gọi L1 sẽ là yếu tố chính dẫn đến phí.
Mặc dù “”Data availability” (Tính sẵn có của dữ liệu) là nút thắt cổ chai đối với các bản tổng hợp ngày nay, nhưng dự kiến rằng điều này sẽ được giảm bớt theo thời gian. Các bản nâng cấp Ethereum như Proto-Danksharding và cuối cùng là Danksharding đầy đủ sẽ giảm đáng kể chi phí đăng dữ liệu lên Ethereum. Ngoài ra, các dự án như Celestia nhằm mục đích cung cấp các chuỗi độc lập được xây dựng có mục đích để cung cấp dữ liệu sẵn có giá rẻ.
Về lâu dài, các hệ thống như Danksharding và Celestia sẽ làm cho dữ liệu sẵn có trở nên rẻ và dồi dào, chuyển nút thắt trở lại hoạt động thực thi. Tuy nhiên, các giải pháp này sẽ cần thời gian để đạt đến độ chín: Celestia vẫn còn vài tháng nữa mới ra mắt mạng chính và có thể phải hơn một năm nữa Ethereum mới có thể bổ sung các nâng cấp về tính khả dụng của dữ liệu như Proto-Danksharding.
Nén dữ liệu cuộc gọi (calldata) để giảm phí Gas trên L1
Nén dữ liệu là một lĩnh vực lâu đời hơn cả máy tính! Được phát minh vào năm 1838, mã Morse là ví dụ sớm nhất được biết đến về nén dữ liệu. Tuy nhiên, việc sử dụng máy tính đã thúc đẩy nghiên cứu về nén dữ liệu, với các thuật toán như mã hóa Huffman được phát minh vào những năm 1950.
Do các bản tổng hợp có khả năng thực thi rẻ nhưng chi phí “Data Available” đắt đỏ nên không có gì ngạc nhiên khi các nhóm này đã tích hợp thuật toán nén dữ liệu vào giao thức của họ. Optimism đã tích hợp thuật toán nén Zlib vào danh sách của họ (Đọc thêm về Algorithm selection process), trong khi bản nâng cấp Nitro sắp tới của Arbitrum sử dụng thuật toán nén brotli.
Các thuật toán nén dữ liệu chắc chắn là công cụ hữu ích giúp giảm chi phí calldata này. Tuy nhiên, nén các giao dịch blockchain là một nhiệm vụ khó khăn: nén dữ liệu hoạt động bằng cách tìm các mẫu phổ biến và rút ngắn chúng. Tuy nhiên, các giao dịch chứa đầy địa chỉ, hàm băm và chữ ký, về cơ bản là “dữ liệu ngẫu nhiên” đối với các thuật toán nén này.
Việc giảm chi phí dữ liệu cuộc gọi thực sự sẽ đến từ việc các nhà phát triển quan tâm hơn đến cách giảm thiểu dữ liệu cuộc gọi trong ứng dụng của họ. Giá gas cao ngất trời trong giai đoạn 2020-2021 đã buộc các nhà phát triển phải tối ưu hóa mã của họ để giảm thiểu việc thực thi và lưu trữ trạng thái.
Khi chuyển sang thế giới L2, trong đó dữ liệu cuộc gọi calldata chuyển từ tài nguyên rẻ nhất sang tài nguyên đắt nhất, các nhà phát triển phải tìm hiểu lại những cách tối ưu hóa mới này.
Một số phương pháp nén dữ liệu cuộc gọi calldata
Dưới đây tổng hợp một số phương pháp nén dữ liệu cuộc gọi, sưu tầm từ các bài viết ở trên mạng và đã được kiểm chứng lại.
Phương pháp 1: Sử dụng encodePacked thay cho encode
Trên Solidity, có 2 hàm giúp bạn đóng gói dữ liệu:
- abi.encode() và abi.decode():
- Đây là hàm để đóng gói dữ liệu nhưng mỗi dữ liệu sẽ thêm phần padding vào để đảm bảo nó vừa 1 slot (32 bytes). Cách đóng gói này khá nhiều phần dữ liệu dư thừa.
- Ví dụ bạn đóng gói (address, uint8, uint8, address, uint8, address) sẽ mất 192 bytes (32×6) để lưu dữ liệu.
encode(0xc35f68eEA89606607e7FEA6f999D1309320B2640, 1, 2, 0xd9aAEc86B65D86f6A7B5B1b0c42FFA531710b6CA, 3, 0xB2B8D40cf9482FcF1deF0aA96a1aD46Fc51b3983) = 0x000000000000000000000000c35f68eea89606607e7fea6f999d1309320b264000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000002000000000000000000000000d9aaec86b65d86f6a7b5b1b0c42ffa531710b6ca0000000000000000000000000000000000000000000000000000000000000003000000000000000000000000b2b8d40cf9482fcf1def0aa96a1ad46fc51b3983
- abi.encodePacked() và abi.decodePacked():
- Là hàm đóng gói dữ liệu mà không có phần đệm dữ liệu, tức là nó sẽ đóng gói theo đúng kích thước dữ liệu. Việc này giúp tối ưu khá nhiều dữ liệu so với hàm abi.encode() ở trên.
- Ví dụ vẫn đóng gói (address, uint8, uint8, address, uint8, address) sẽ chỉ mất 63 bytes (20*3+1*3) để lưu dữ liệu.
encode(0xc35f68eEA89606607e7FEA6f999D1309320B2640, 1, 2, 0xd9aAEc86B65D86f6A7B5B1b0c42FFA531710b6CA, 3, 0xB2B8D40cf9482FcF1deF0aA96a1aD46Fc51b3983) = 0xc35f68eea89606607e7fea6f999d1309320b26400102d9aaec86b65d86f6a7b5b1b0c42ffa531710b6ca03b2b8d40cf9482fcf1def0aa96a1ad46fc51b3983
Rõ ràng sử dụng encodePacked() tốt hơn khá nhiều, nhưng thực tế có nhiều trường hợp ta vẫn có thể nén thêm được nữa. Chẳng hạn như kiểu uint256, phần lớn thì giá trị của nó rất nhỏ thì sẽ có rất nhiều số 0 đằng trước rất lãng phí, nhưng đôi khi nó là số lớn lấp đầy hết 256 bit. Vậy làm sao để hiệu quả trong trường hợp này.
Thêm nữa với cấu trúc struct, thì bạn cần chú ý thứ tự các trường dữ liệu trong cấu trúc, nếu không cẩn thận sẽ tăng kích thước dữ liệu lên rất nhiều.
Phương pháp 2: Tight-Packing – Đóng gói chặt
Theo phương pháp này, chúng ta sẽ tìm cách để đóng gói dữ liệu theo thứ tự tối ưu nhất để làm sao được kích thước nhỏ nhất về phần Storage. Quá trình đóng gói lại là Đóng gói chặt (Tight-Packing), để đạt được điều này thì có hai vấn đề cần chú ý:
- Hãy chọn kiểu dữ liệu cho phù hợp để đảm bảo được vùng giá trị và cần ít byte để lưu trữ nhất
- Thứ tự các biến / các trường dữ liệu rất quan trọng, phải sắp xếp làm sao để sử dụng ít slot nhất có thể.
- Dùng cơ chế mapping hoặc sử dụng contract khác để giúp giảm dữ liệu đầu vào
- Có thể bỏ 4 bytes của “function selector”
Ví dụ: Đóng gói dữ liệu cho 1 struct => Chi tiết xem bài viết: Tight Variable Packing
Trên EVM có khái niệm là slot, mỗi slot tương ứng 32 bytes. Các kiểu dữ liệu phổ biến như bytes32, uint, int chiếm chính xác 1 slot. Với các kiểu dữ liệu nhỏ hơn như byte15, uint32,… thì EVM có thể đóng gói chúng lại trong một slot duy nhất, do đó sẽ tiết kiệm bộ nhớ hơn.
Cách này được sử dụng cho các biến trạng thái, các trường dữ liệu bên trong cấu trúc struct, và cho các mảng có kích thước cố định. Dưới đây là ví dụ sử dụng phương pháp này trong 1 cấu trúc:
// This code has not been professionally audited, therefore I cannot make any promises about
// safety or correctness. Use at own risk.
contract StructPackingExample {
struct CheapStruct {
uint8 a;
uint8 b;
uint8 c;
uint8 d;
bytes1 e;
bytes1 f;
bytes1 g;
bytes1 h;
}
CheapStruct example;
function addCheapStruct() public {
CheapStruct memory someStruct = CheapStruct(1,2,3,4,"a","b","c","d");
example = someStruct;
}
}Như khai báo trên, cấu trúc CheapStruct sẽ được lưu trữ trong 1 slot.
Phương pháp 3: Nén dữ liệu kết hợp nhiều phương pháp giảm calldata từ 100 bytes về còn 9 bytes
Chúng ta xem xét một ví dụ khác, đó là giao dịch chuyển token cho một người khác. Phần này tham khảo từ bài viết Crunching the Calldata (Bài viết này khá hay, các bạn nên đọc). Bài viết này sẽ nói về 3 phương pháp để từng bước giảm dữ liệu đầu vào.
B1: Sử dụng Đóng gói chặt
Giao dịch cơ bản thực hiện trên Arbitrum sử dụng 576051 ArbiGas, với tổng phí là $0.43. Dữ liệu của giao dịch này như dưới:

Ta sẽ thấy có rất nhiều dữ liệu thừa mà ta có thể loại bỏ. Bây giờ chúng ta thực hiện Tight-Packing đơn giản như sau:
- Đầu tiên ta sẽ loại bỏ hết các số 0 thêm vào như là padding. Mặc dù số 0 rẻ hơn byte khác 0 nhưng chúng vẫn phải trả phí => Ta có dùng encodePacked() để làm việc này.
- Có 4 bytes đầu xác định “function signature” giúp Solidity biết được hàm mà chúng ta cần gọi. Chúng ta có thể loại bỏ 4 bytes này. Trước khi đọc bài này, thực tế tôi cũng chưa biết làm thế nào để làm được vậy. Sau khi xem source code của Smart contract trên ArbiScan và bài Sending Ether (transfer, send, call), thì tôi cũng đã biết làm thế nào để làm được điều này. Hóa ra cách làm như sau:
- B1: Trên Smart Contract bạn cài đặt thêm hàm dưới và xử lý data trong hàm này. Hàm này được gọi khi bạn thực hiện lệnh chuyển ETH có kèm data đến Smart Contract:
fallback() external
Tôi đã triển khai trên Goerli với địa chỉ Smart Contract như sau: 0x3AFf557F7B724F7b778387Bb85dC35C97f581461 - B2: Bên dưới bạn viết đoạn code nhỏ thực hiện chuyển 0 ETH kèm data bất kỳ mà bạn muốn tới Smart Contract. Tôi thử 2 giao dịch, thấy dữ liệu “Input Data” hoàn toàn giống với dữ liệu gửi lên, không có bất kỳ padding nào và theo cách này ta không cần phải có 4 bytes để xác định selector làm gì:
- Giao dịch 1: Chuyển 0 ETH với data là 0x0123456789abcdef
- Giao dịch 2: Chuyển 0 ETH với data là 0x11223344556677881122334455667788
- B1: Trên Smart Contract bạn cài đặt thêm hàm dưới và xử lý data trong hàm này. Hàm này được gọi khi bạn thực hiện lệnh chuyển ETH có kèm data đến Smart Contract:
Với 2 tối ưu trên, chúng ta giảm từ 100 bytes xuống còn 43 bytes. Giao dịch mới của chúng ta chỉ sử dụng 494485 ArbiGas (Giảm 14%) với phí là $0.37$:

B2: Giảm thêm dữ liệu bằng cách sử dụng contract “Helper”
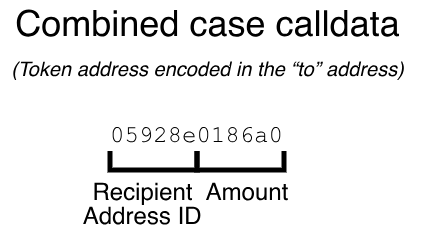
Chúng ta để ý rằng, phần lớn dữ liệu được tạo thành từ 2 địa chỉ:
- Một địa chỉ cho mã thông báo
- Một địa chỉ cho người nhận
Tuy nhiên chúng ta tưởng tượng rằng hầu hết người dùng đang chuyển cùng một số token (WETH, DAI, USDC). Một cách để chúng ta có thể xóa toàn bộ địa chỉ mã thông báo khỏi dữ liệu cuộc gọi của mình là triển khai hợp đồng “trợ giúp” đặc biệt cho mã thông báo đó. Bây giờ chúng ta gửi giao dịch của mình đến người trợ giúp này, hoàn toàn tránh được nhu cầu bao gồm địa chỉ mã thông báo. Điều này cho phép chúng ta giảm mã byte dữ liệu xuống còn 23 byte. Giao dịch thử nghiệm của chúng ta đã sử dụng 457546 (giảm 21% so với kiểm soát) và có giá $0.34:

B3: Giảm thêm dữ liệu bằng phương pháp “Bảng tra địa chỉ (Address lookup-table)”
Mặc dù ở phần trên chúng ta đã dùng “Helper contract” để loại bỏ 1 địa chỉ khỏi dữ liệu calldata, tuy nhiên vẫn còn 1 địa chỉ khác trong dữ liệu calldata. Vậy liệu có phương pháp nào nhất quán hơn để “nén” dữ liệu địa chỉ không?
Rất may, Arbitrum có một hợp đồng tích hợp được gọi là “Address Table Registry“, chúng ta có thể sử dụng hợp đồng này để rút ngắn dữ liệu cuộc gọi của mình. Hợp đồng này về cơ bản là 1 “phone-book” (Danh bạ điện thoại) để ánh xạ các địa chỉ 20 bytes thành các số nguyên đơn giản. Kiểu như ta chỉ cần biết số thứ tự địa chỉ trong danh bạ, thì ta sẽ tìm ra địa chỉ đó.
Bằng cách thay thế cả địa chỉ “mã thông báo” và “người nhận“, chúng ta có thể giảm dữ liệu cuộc gọi xuống còn 9 byte. Giao dịch thử nghiệm của chúng ta đã sử dụng 428347 (giảm 26% so với kiểm soát) và có giá $0.32

B4: Kết hợp tất cả các kỹ thuật trên
Cuối cùng, hãy kết hợp tất cả các kỹ thuật của chúng ta thành một:
- Xóa phần đệm và bộ chọn chức năng
- Sử dụng hợp đồng trợ giúp xác định để xóa các địa chỉ chung
- Sử dụng bảng địa chỉ Arbitrum để rút gọn các địa chỉ khác
Nhìn chung, kích thước dữ liệu cuộc gọi của chúng ta hiện chỉ là 6 byte! Giao dịch thử nghiệm cuối cùng đã sử dụng 426529 (cũng giảm 26% so với kiểm soát, thấp hơn một chút so với trường hợp thử nghiệm trước đó) và có giá $0.32.
Dưới đây là biểu đồ tổng kết lại để so sánh giữa các phương pháp:

Phương pháp 3: Nén dữ liệu
Dữ liệu sau khi đóng gói được nén thêm lần nữa để giảm kích thước dữ liệu. Chi tiết xem bài viết: Crunching the Calldata
Các Layer 2 cũng sử dụng nén dữ liệu để tối ưu hóa kích thước dữ liệu trước khi đẩy lên L1:
- Optimism tích hợp thuật toán nén Zlib. Xem thêm: The Road to Sub-dollar Transactions, Part 2: Compression Edition
- Arbitrum, bản nâng cấp Nitro, tích hợp thuật toán nén Brotli.
Tất nhiên, các Layer 2 sử dụng thuật toán nén ở phía Offchain, nên nó cũng sẽ đơn giản hơn nhiều so với Onchain.
Phương pháp nén không mất dữ liệu
Kỹ thuật Tight-Packing nói ở phần trên cũng có thể coi là một phương pháp “NÉN” không mất mát dữ liệu.
Tôi tìm thấy một phương pháp encode dữ liệu sử dụng RPL từ một bạn trên Reddit đề xuất: Calldata compression via RLP và RECURSIVE-LENGTH PREFIX (RLP) SERIALIZATION. Cũng đã có những đề xuất thiết kế ABIv3 giúp giảm dữ liệu calldata: An ABIv3 design for tiny calldata. Tôi tìm thấy có bản RLP (RLP.sol và RPL Library On NodeJs) đã cài đặt sẵn (Theo bài viết: How to RLP-encode messages in Solidity). Nhưng khi chạy thử 1 vài data thì thấy sau khi encode, dữ liệu còn nhiều hơn cả ban đầu. Như vậy đây không phải là giải pháp cần tìm kiếm.
Ngoài ra bạn có thể tham khảo 1Inch có sử dụng phương pháp nén dữ liệu (Calldata Compressor and Decompressor), chi tiết bạn xem:
- Phần nén dữ liệu bằng Javascript: compressor.js
- Giải nén dữ liệu bằng Solidity: DecompressorExtension.sol
<Phần này tôi đang nghiên cứu thêm và sẽ cập nhật thêm sau>
Phương pháp nén mất mát dữ liệu
Trong thực tế, cũng giống như các tệp ảnh và video sử dụng thuật toán “nén mất dữ liệu” để loại bỏ những thông tin không cần thiết, chúng ta cũng có thể loại bỏ những dữ liệu không cần thiết trong hầu hết các trường hợp.
Các ví dụ chính của việc này là rút ngắn số để loại bỏ độ chính xác không cần thiết. Ví dụ: mã thông báo ERC-20 thường duy trì độ chính xác 18 chữ số thập phân, tuy nhiên hầu hết người dùng thường chỉ quan tâm đến tối đa ~ 4 chữ số thập phân. Theo mặc định, chúng tôi có thể xây dựng một hợp đồng chấp nhận các số có 8 chữ số thập phân và nhân với 10^10, với chức năng phụ dành cho những người dùng yêu cầu độ chính xác cao hơn.
Tương tự, ngày thường được biểu diễn dưới dạng “số giây kể từ ngày 1 tháng 1 năm 1970” (còn được gọi là thời gian Unix). Các hợp đồng có thể giảm kích thước của số nguyên này bằng cách chấp nhận thời gian là phút, giờ hoặc ngày thay vào đó và có thể đặt “epoch” (kỷ nguyên) của riêng chúng, ví dụ: ngày 1 tháng 1 năm 2015.
Tham khảo:

















Trả lời