
Hiện có nhiều công cụ để giám sát server như Zabbix, Nagios, Cacti, Centreon, MRTG, Grafana+Prometheus,.. Mỗi hệ thống đều có điểm mạnh và điểm yếu khác nhau, do đó trước khi sử dụng chúng ta cần cân nhắc kỹ. Nhưng với yêu cầu giám sát đơn giản thì Prometheus và Grafana là khá đủ để sử dụng.
Mục lục
So sánh đánh giá 3 nền tảng giám sát máy chủ: Nagios, Zabbix và Prometheus
Nagios, Zabbix và Prometheus đều là những giải pháp giám sát cơ sở hạ tầng CNTT phổ biến. Tuy nhiên, Nagios Core thiếu nhiều tính năng quan trọng có trong Zabbix và Prometheus, trừ khi bạn sẵn sàng trả tiền cho phiên bản thương mại (Nagios XI).
Zabbix và Prometheus đều là những nền tảng xuất sắc nhưng có những điểm mạnh khác nhau. Prometheus dễ cài đặt hơn và thu thập dữ liệu tốt hơn nhờ ngôn ngữ truy vấn mạnh mẽ (PromQL). Nó cũng có một cộng đồng lớn hơn đáng kể, nơi bạn có thể nhận được hỗ trợ trong khi định cấu hình nó để đáp ứng nhu cầu của mình.
Khi nói đến trực quan hóa dữ liệu, Zabbix rõ ràng chiếm ưu thế. Không giống như Prometheus, bạn có thể tạo biểu đồ, bản đồ và trang tổng quan mà không cần dựa vào các dịch vụ của bên thứ ba như Grafana. Zabbix cũng có giao diện người dùng được thiết kế tốt hơn, giải pháp quản lý người dùng tốt hơn và chức năng cảnh báo tốt hơn.
- Nagios Core:
- Là một ứng dụng mã nguồn mở và miễn phí có thể giám sát các máy chủ và dịch vụ của bạn cũng như cảnh báo cho bạn khi có sự cố. Nó được viết bởi Ethan Galstad và một nhóm các nhà phát triển như một chương trình giám sát hệ thống Linux, nhưng nó có thể được cài đặt trên các biến thể Unix khác.
- Nagios Core thiếu nhiều tính năng quan trọng có trong Zabbix và Prometheus, trừ khi bạn sẵn sàng trả tiền cho phiên bản thương mại (Nagios XI).
- Zabbix:
- Là một phần mềm nguồn mở khác được thiết kế chủ yếu để giám sát cơ sở hạ tầng CNTT. Nó được phát hành lần đầu tiên vào năm 2004 và vẫn đang được phát triển tích cực với các bản phát hành mới sáu tháng một lần.
- Cuối cùng, Prometheus là một công cụ giám sát máy chủ có thể thu thập dữ liệu chuỗi thời gian từ máy chủ của bạn và biên dịch chúng thành biểu đồ. Ban đầu nó được tạo bởi SoundCloud và hiện là một dự án nguồn mở được lưu trữ trên GitHub.

Chi tiết các bạn xem bài viết: Nagios vs Zabbix vs Prometheus: The Key Differences to Know
Hiện tại Prometheus sử dụng kết hợp với Grafana đều là miễn phí, cài đặt dễ dàng và đang được sử dụng rộng rãi hơn. Vì thế bài viết này sẽ tập trung vào Hướng dẫn sử dụng Prometheus và Grafana để giám sát hệ thống server.
Tìm hiểu về Prometheus và Grafana
Tổng quan Prometheus và Grafana
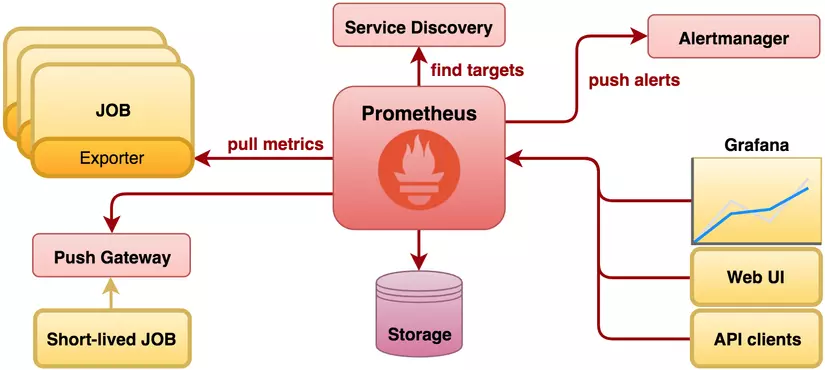
Prometheus và Grafana là bộ công cụ thường sử dụng cùng nhau để tạo nên hệ thống giám sát dữ liệu (Logs, CPU, RAM, Disk, IO operations…) trực quan. Trong đó:
- Prometheus được dùng để giám sát hệ thống thông qua các daemon cài sẵn trên các node, qua đó thu thập các thông tin cần thiết. Prometheus giao tiếp với node qua giao thức http/https và lưu trữ data theo dạng time-series database (TSDB).
- Prometheus sẽ thực hiện quá trình kéo (pull) các thông số/số liệu (metric) từ các job (exporter).
- Prometheus sẽ lưu trữ các dữ liệu thu thập được ở local máy chủ.
- Prometheus sẽ chạy các rule để xử lý các dữ liệu theo nhu cầu cũng như kiểm tra thực hiện các cảnh báo mà bạn mong muốn.
- Grafana là một giao diện hiển thị các metric dưới dạng các biểu đồ (chart) hoặc đồ thị (graph), được tập hợp lại thành dashboard có tính tùy biến cao, giúp dễ dàng theo dõi tình trạng của node.
Đơn giản cho các bạn dễ hiểu là sau khi lấy được metric từ các thiết bị, grafana sẽ sử dụng metric đó để phân tích và tạo ra dashboard mô tả trực quan các metric cần thiết cho việc monitoring như CPU, RAM, disks, IO operations…
Việc sử dụng Prometheus và Grafana cũng sẽ giúp chúng ta không bị phụ thuộc vào dịch vụ của các bên như AWS (Amazon Web Services), GCP (Google Cloud Platform), mà lại có thể giám sát server một cách tập trung không cần biết chúng ta đang sử dụng dịch vụ bên nào. Mặt khác việc sử dụng dịch vụ bên khác như AWS hay GCP, có khi chúng ta cũng cần phải trả phí thêm khá cao so với nhu cầu.
Hướng dẫn cài đặt, cấu hình và sử dụng Prometheus và Grafana
Cài đặt Node Exporter
Trên các máy cần giám sát, chúng ta cần cài Node Exporter. Đây là công cụ giúp thu thập dữ liệu cần giám sát, gồm các thông tin như CPU, RAM, Disk, Network,…
Cài đặt Node Exporter – Bản Standalone
Bạn truy cập vào trang Node Exporter Releases để tìm bản mới nhất và tải xuống. Tôi sử dụng lệnh sau để tải và cài đặt:
# Tải ứng dụng
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
# Giải nén
tar -xzf node_exporter-1.7.0.linux-amd64.tar.gz
# Xóa tệp tải về
rm node_exporter-1.7.0.linux-amd64.tar.gz
# Đổi tên
mv node_exporter-1.7.0.linux-amd64 node_exporter-1.7.0
# Vào thư mục ứng dụng
cd node_exporter-1.7.0
# Kiểm tra phiên bản
./node_exporter --version
# Chạy ứng dụng
./node_exporterThông thường chúng ta sẽ chạy ở cấu hình mặc định, tức ở port 9100 và đường dẫn lấy dữ liệu là /metrics. Trong trường hợp bạn muốn thay đổi hai thông số này thì bạn sử dụng lệnh sau:
# Sử dụng tham số web.listen-address và web.telemetry-path để thay đổi cấu hình mặc định
node_exporter --web.listen-address=":9600" --web.telemetry-path="/node_metrics"Cài đặt Node Exporter dưới dạng dịch vụ
Chạy ứng dụng kiểu Standalone hơi bất tiện nếu server có vấn đề cần phải khởi động lại thì ta phải chạy lại ứng dụng thủ công. Vì thế chúng ta nên chuyển sang sử dụng dịch vụ sẽ tiện hơn rất nhiều.
Đầu tiên chúng ta vẫn phải tải về như bước ở trên, sau đó thực hiện thêm một số bước như sau:
# Chuyển Node Exporter tới thư mục /usr/local/bin/
cd ..
sudo cp node_exporter-1.7.0/node_exporter /usr/local/bin/
# Tạo user node_exporter để chạy dịch vụ
sudo useradd -rs /bin/false node_exporter
# Tạo tệp service
# Nội dung tệp xem bên dưới
sudo nano /etc/systemd/system/node_exporter.service
# Xóa thư mục thừa nếu cần
rm -rf node_exporter-1.7.0Nội dung tệp node_exporter.service như sau:
[Unit]
Description=Node Exporter
After=network.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.targetBây giờ chúng ta reload lại System Daemon và start dịch vụ:
# Reload lại System Daemon
sudo systemctl daemon-reload
# Bật dịch vụ tự chạy khi khởi động
sudo systemctl enable node_exporter
# Bật dịch vụ
sudo service node_exporter start
# Xem trạng thái dịch vụ
sudo service node_exporter status
# Tắt dịch vụ
sudo service node_exporter stopCài đặt Prometheus
Prometheus là một dịch vụ theo dõi và cảnh báo về hệ thống. Đây là một dịch vụ mã nguồn mở (Open source) hoàn toàn miễn phí. SoundCloud đã khởi đầu xây dựng Prometheus từ năm 2012. Prometheus đã được rất nhiều hệ thống tin tưởng áp dụng. Dự án có một cộng đồng người đóng góp, phát triển rất tích cực. Giờ đây Prometheus đã được tách khỏi SoundCloud và là một dự án mã nguồn mở độc lập. Năm 2016, Prometheus tham gia vào tổ chức CNCF (Cloud Native Computing Foundation) với vị trí được ưu tiên phát triển thứ hai sau K8s (Kubernetes).
Bạn vào trang Prometheus Download để chọn phiên bản phù hợp, mình sử dụng Ubuntu 18.04.6 nên sử dụng bản cho Ubuntu:
# Tải prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.49.1/prometheus-2.49.1.linux-amd64.tar.gz
# Giải nén bẳng tar
tar -xzf prometheus-2.49.1.linux-amd64.tar.gz
# Xóa tệp cài đặt và đổi tên thư mục
rm prometheus-2.39.0.linux-amd64.tar.gz
mv prometheus-2.49.1.linux-amd64 prometheus-2.49.1
# Vào thư mục
cd prometheus-2.49.1
# Kiểm tra phiên bản
./prometheus --version
# Chạy prometheus
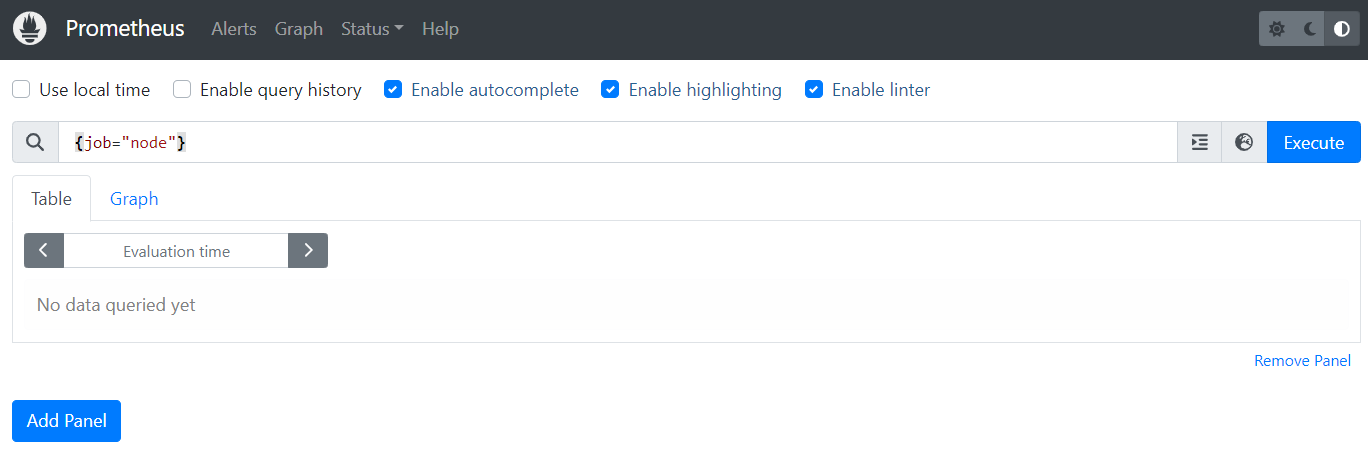
./prometheus --config.file prometheus.ymlSau khi chạy xong, mở trình duyệt vào link http://localhost:9090/ bạn sẽ thấy giao diện như ảnh dưới. Trong giao diện này bạn có thể kiểm tra các job đang chạy và truy vấn dữ liệu:
- Kiểm tra job đang chạy: http://localhost:9090/tsdb-status
- Truy vấn dữ liệu: http://localhost:9090/graph (Sử dụng ngôn ngữ PromQL để truy vấn dữ liệu). Ví dụ:
{job=”node”}
{job=”prometheus”}[5m]
rate(node_cpu_seconds_total{mode=”system”}[1m])
rate(node_network_receive_bytes_total[1m])
Để thay đổi cấu hình bạn sửa tệp prometheus.yml, mặc định tệp này như sau:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]Để thu thập dữ liệu từ nhiều server khác nhau chúng ta thêm job mới tên là “node”, cụ thể xem phần dưới. Nhưng để dữ liệu dễ nhìn chúng ta ánh xa IP sang tên miền trước bằng cách trên server cài đặt prometheus, chú ta sửa tệp “/etc/hosts” thêm vào các dòng sau vào cuối tệp:
x.x.x.x frontend
y.y.y.y database
z.z.z.z serviceSau đó ta sửa tệp prometheus.yml như sau:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node"
static_configs:
- targets: ["frontend:9100"]
- targets: ["database:9100"]
- targets: ["service:9100"]Cài đặt và cấu hình Grafana
Grafana là một hệ thống mã nguồn mở cung cấp giao diện hiển thị trực quan các dữ liệu thu thập được từ Prometheus.
Bạn vào trang Grafana Download để chọn phiên bản phù hợp và có cả hướng dẫn cài đặt luôn. Do sử dụng bản Standalone nên lệnh cài đặt như sau:
# Tải bản cài đặt
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-10.3.1.linux-amd64.tar.gz
# Giải nén
tar -zxvf grafana-enterprise-10.3.1.linux-amd64.tar.gz
# Xóa tệp cài đặt
rm grafana-enterprise-10.3.1.linux-amd64.tar.gz
# Vào thư mục ứng dụng
cd grafana-v10.3.1
# Sửa cấu hình nếu muốn
# http_port: Cấu hình port của UI
nano conf/defaults.ini
# Chạy Grafana
./bin/grafana-serverNếu sử dụng bản cài đặt, bạn có thể dùng lệnh sau:
# Cài đặt
sudo apt-get install -y adduser libfontconfig1 musl
wget https://dl.grafana.com/enterprise/release/grafana-enterprise_10.3.1_amd64.deb
sudo dpkg -i grafana-enterprise_10.3.1_amd64.deb
# Bật chế độ chạy mặc định khi khởi động
sudo systemctl enable grafana-server.service
# Chạy grafana
sudo service grafana-server startBây giờ chúng ta vào trình duyệt, mở link http://localhost:3000, và đăng nhập vào với tài khoản mặc định admin / admin, sau đó đổi mật khẩu mới, sau khi hoàn thành sẽ thấy giao diện như hình vẽ:

Như theo hướng dẫn để hiển thị được dữ liệu bạn phải làm hai việc:
- Thêm mới “Data Source”:
- B1: Trên giao diện Dashboard ta kích vào “Add your first data source”, hoặc trên Menu trái ta chọn “Connections -> Data sources“
- B2: Ta chọn prometheus, sau đó phần URL nhập “http://localhost:9090“, còn các cấu hình khác mặc định, sau đó nhấn “Save & test“. Hiện tại thấy hỗ trợ 152 kiểu Data Source khác nhau.
- Tạo Dashboard để hiển thị dữ liệu:
- B1: Trên giao diện Dashboard, ta kích vào “Create your first dashboard“, hoặc trên menu trái chọn “Dashboards -> New -> Import“. Việc tự tạo Dashboard hơi mất công nên ta sử dụng 1 trong các dashboard trên Grafana Dashboards, có nhiều template đẹp, hiển thị thông tin khác nhau tùy mục đích sử dụng. Đã xem nhiều mẫu thích nhất mẫu 11074, ta nhập ID 11074 vào rồi nhấn Load, sau đó bạn đổi tên và chọn Data Source, rồi nhấn nút Import. Ngoài ra tôi thấy nhiều mẫu khác hiển thị tập trung vào dữ liệu cần thiết, bạn nên tham khảo:
- 11074 – Node Exporter Dashboard EN 20201010-StarsL.cn
- 15172 – Node Exporter for Prometheus Dashboard based on 11074
- 1860 – Node Exporter Full: Mẫu này khá nhiều thông tin, chắc dành cho DevOpts chuyên nghiệp, mình nhìn không quen lắm.
- 6417 – Kybernetes Cluster
- 7249 – Kubernetes Cluster
- 8171 – Kubernetes Nodes
- 11956 – Nodejs Metrics
- 2583 – MongoDB
- B2: Sau khi Import thì vào lại giao diện để xem
- B1: Trên giao diện Dashboard, ta kích vào “Create your first dashboard“, hoặc trên menu trái chọn “Dashboards -> New -> Import“. Việc tự tạo Dashboard hơi mất công nên ta sử dụng 1 trong các dashboard trên Grafana Dashboards, có nhiều template đẹp, hiển thị thông tin khác nhau tùy mục đích sử dụng. Đã xem nhiều mẫu thích nhất mẫu 11074, ta nhập ID 11074 vào rồi nhấn Load, sau đó bạn đổi tên và chọn Data Source, rồi nhấn nút Import. Ngoài ra tôi thấy nhiều mẫu khác hiển thị tập trung vào dữ liệu cần thiết, bạn nên tham khảo:
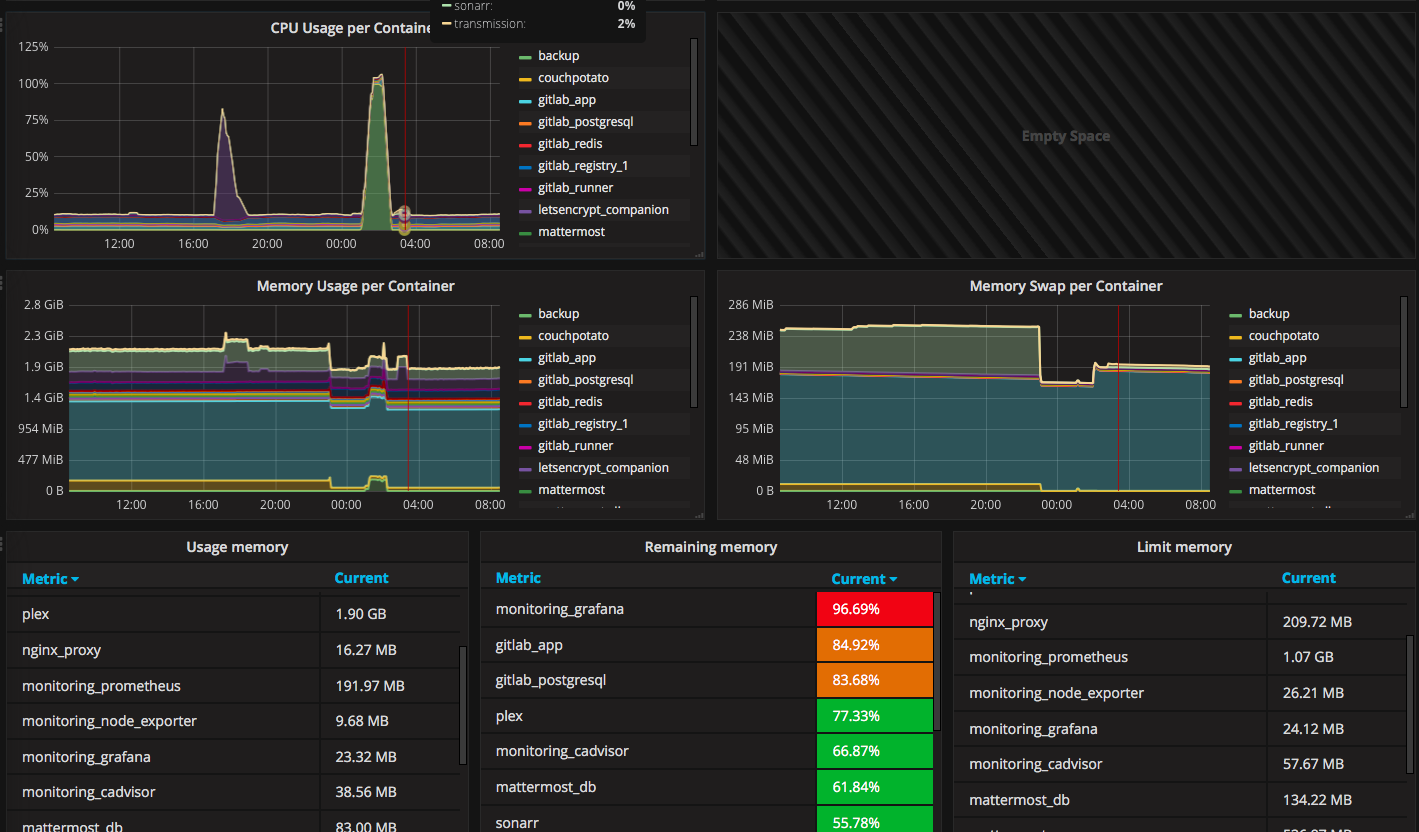
Sau khi xong, chúng ta nhìn thấy Dashboard hiển thị như sau (Còn rất nhiều chart ở bên dưới):



Cấu hình cảnh báo trong Prometheus gửi tin nhắn qua Telegram
Telegram hiện tại thông dụng, đặc biệt với dân Crypto, vì thế mong muốn cấu hình để cảnh báo qua Telegram. May mắn mình đã tìm thấy bài viết Cấu Hình Alert Trong Prometheus Gửi Tin Nhắn Qua Telegram
B1: Cài đặt và khởi chạy AlertManager
Các bước cài đặt như sau:
# Tải alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.20.0/alertmanager-0.20.0.linux-amd64.tar.gz
# Giải nén và xóa tệp tải về
tar -xvzf alertmanager-0.20.0.linux-amd64.tar.gz
rm alertmanager-0.20.0.linux-amd64.tar.gz
# Đẩy vào thư mục /usr/local
sudo mv alertmanager-0.20.0.linux-amd64 /usr/local/alertmanager
# Tạo tệp service, nội dung xem phần dưới
sudo nano /etc/systemd/system/alertmanager.serviceNội dung tệp alertmanager.service:
[Unit]
Description=AlertManager
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.targetBây giờ chúng ta bật dịch vụ:
# Cấu hình để tự bật dịch vụ khi server khởi động
sudo systemctl daemon-reload
sudo systemctl enable alertmanager
# Bật dịch vụ
sudo service alertmanager start
# Tắt dịch vụ
sudo service alertmanager stop
# Xem trạng thái
sudo service alertmanager statusSau khi khởi chạy, AlertManager sẽ sử dụng port mặc định 9093.
B2: Tạo các tệp rule xác định quy tắc cảnh báo
Trước khi tạo tệp rule, chúng ta phải biết một số công thức tính toán trước đã, chi tiết xem bài: Best practices for configuring alert rules in Prometheus, Awesome Prometheus alerts và Prometheus alert rules for node exporter. Dưới đây là một số công thức tính toán, bạn có thể kiểm tra trực tiếp trên giao diện của Prometheus:
- Công thức tính tỉ lệ RAM chưa sử dụng: Đơn vị %
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 - Công thức tính tỉ lệ sử dụng CPU: Đơn vị %
100 – (avg by(instance) (rate(node_cpu_seconds_total{mode=”idle”}[2m])) * 100) - Công thức tính tỉ lệ Storage còn trống: Đơn vị %
((node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes) - Xác định một VPS có vấn đề thông qua kiểm tra job “node” bằng điều kiện sau:
up{job=”node”}==0
Vào thư mục của prometheus, bây giờ ta sẽ tạo thêm các tệp rule như dưới. Về một số công thức tính toán bạn xem tại:
Đầu tiên tạo tệp global_alert_rules.yml như sau:
############# Define Rule Alert ###############
# My global alert config
############# Define Rule Alert ###############
groups:
- name: global-alert
rules:
################ Server Status
- alert: Server Status
expr: up{job="node"}==0
for: 5m
labels:
severity: error
annotations:
summary: "Server Status (instance {{ $labels.instance }})"
description: "Server state is not OK\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
################ Memory Usage High
- alert: Memory Usage Very High
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 5m
labels:
severity: error
annotations:
summary: "Memory Usage (instance {{ $labels.instance }})"
description: "Memory Usage is more than 90%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: Memory Usage High
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 20
for: 15m
labels:
severity: warning
annotations:
summary: "Memory Usage (instance {{ $labels.instance }})"
description: "Memory Usage is more than 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
################ CPU Usage High
- alert: Cpu Usage Very High
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 90
for: 5m
labels:
severity: error
annotations:
summary: "CPU Usage (instance {{ $labels.instance }})"
description: "CPU Usage is more than 90%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: Cpu Usage High
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80
for: 15m
labels:
severity: warning
annotations:
summary: "CPU Usage (instance {{ $labels.instance }})"
description: "CPU Usage is more than 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
################ Disk Usage
- alert: Disk SpaceUsage Very High
expr: ((node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes) < 5
for: 5m
labels:
severity: error
annotations:
summary: "Disk Space Usage (instance {{ $labels.instance }})"
description: "Disk Space on Drive is used more than 95%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: Disk SpaceUsage High
expr: ((node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes) < 20
for: 5m
labels:
severity: warning
annotations:
summary: "Disk Space Usage (instance {{ $labels.instance }})"
description: "Disk Space on Drive is used more than 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"Bạn cũng có thể tạo thêm nhiều tệp rule khác. Tệp rule này rất hay gặp lỗi khi soạn thảo vì thế nên kiểm tra trước.
Nếu chúng ta đã cấu hình tệp rule này trong tệp prometheus.yml thì chúng ta có thể kiểm tra toàn bộ cấu hình bằng lệnh sau:
./promtool check config prometheus.ymlKhông thì chúng ta có thể sử dụng công cụ pint để kiểm tra trước. Cách sử dụng như sau:
# Tải ứng dụng pint
wget https://github.com/cloudflare/pint/releases/download/v0.53.0/pint-0.53.0-linux-amd64.tar.gz
# Giải nén và xóa tệp tải về
tar -zxvf pint-0.53.0-linux-amd64.tar.gz
rm pint-0.53.0-linux-amd64.tar.gz
# Sử dụng pint để kiểm tra tệp rule
./pint-linux-amd64 lint ./prometheus-2.49.1/global_alert_rules.ymlMàn hình thông báo như dưới là OKIE:

B2: Cấu hình alert trong prometheus
Vào lại thư mục của prometheus và sửa tệp prometheus.yml. Nội dung sửa trong phần bôi đậm:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "global_alert_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node"
static_configs:
- targets: ["frontend:9100"]
- targets: ["database:9100"]
- targets: ["service:9100"]B3: Cài đặt và cấu hình prometheus_bot để gửi thông báo qua Telegram
Đầu tiên bạn phải cài đăt Go, xem hướng dẫn: Cài đặt Go. Tiếp theo bạn token sử dụng cho TelegramBot, xem hướng dẫn: Làm thế nào để tạo riêng của bạn Telegram bot
Bây giờ chúng ta cài đặt prometheus_bot bằng lệnh sau:
# Tải mã nguồn
git clone https://github.com/inCaller/prometheus_bot.git
# Build mã nguồn
cd prometheus_bot
make clean
make
# Copy vào thư mục /usr/local
sudo mkdir /usr/local/prometheus_bot
sudo cp prometheus_bot /usr/local/prometheus_bot
# Tạo tệp cấu hình cho prometheus_bot
# Nội dung xem bên dưới
sudo nano /usr/local/prometheus_bot/config.yaml
# Sao chép template gửi tin nhắn
sudo cp testdata/production_example.tmpl /usr/local/prometheus_bot/template.tmpl
# Test thử bằng lệnh, nhớ đổi lại chat_id
cp /usr/local/prometheus_bot/config.yaml .
export TELEGRAM_CHATID="-364942581"
make testNội dung tệp config.yaml như sau (Nhớ đổi telegram_token nhé):
telegram_token: "997872129:AAEPKYz3nPwmFsgq6ao-MdPsC5fy5z376GQ"
# ONLY IF YOU USING TEMPLATE required for test
# template_path: "/usr/local/prometheus_bot/template.tmpl"
time_zone: "Asia/Ho_Chi_Minh"
split_token: "|"
# ONLY IF YOU USING DATA FORMATTING FUNCTION, NOTE for developer: important or test fail
time_outdata: "02/01/2006 15:04:05"
split_msg_byte: 4000Bây giờ chúng ta tạo service chạy prometheus_bot bằng cách tạo tệp /etc/systemd/system/prometheus_bot.service với nội dung như sau:
[Unit]
Description=Prometheus Bot
After=network.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/usr/local/prometheus_bot/prometheus_bot -c /usr/local/prometheus_bot/config.yaml
[Install]
WantedBy=multi-user.targetCác lệnh chạy dịch vụ:
# Cấu hình để tự bật dịch vụ khi server khởi động
sudo systemctl daemon-reload
sudo systemctl enable prometheus_bot
# Bật dịch vụ
sudo service prometheus_bot start
# Tắt dịch vụ
sudo service prometheus_bot stop
# Xem trạng thái
sudo service prometheus_bot statusB4: Cấu hình lại alertmanager
Bây giờ ta sửa tệp /usr/local/alertmanager/alertmanager.yml, đổi tham số url và cập nhật một số tham số khác:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 5m
repeat_interval: 30m
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://localhost:9087/alert/-364942581'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']B4: Chạy lại các dịch vụ
Bây giờ chúng ta chạy lại các dịch vụ bằng lệnh sau:
sudo service prometheus_bot restart
sudo service alertmanager restart
service prometheus restartKiểm tra kết quả trong Prometheus/Alert: http://dex-scanner.com:9090/alerts
Một số thao tác khác
Xóa dữ liệu của 1 Instance
Thông thường mỗi server theo dõi sẽ tương đương với 1 instance. Bây giờ nếu chúng ta tắt 1 server thì dữ liệu server đó vẫn còn trên hệ thống và hệ thống Prometheus sẽ vẫn có cảnh báo và liên tục sau bao nhiêu phút:
[FIRING:1]
grouped by: alertname=Server Status
labels: instance=server-tracking-01:9100, job=node, severity=error
description: Server state is not OK
VALUE = 0
LABELS: map[__name__:up instance:server-tracking-01 job:node]
summary: Server Status (instance server-tracking-01)Để loại bỏ cảnh báo này, chúng ta đầu tiên cần stop Prometheus, sau đó sửa tệp prometheus.yml để bỏ theo dõi server vừa tắt.
Tiếp theo chúng ta cần xóa hết dữ liệu “Time Series” của một instance. Việc này chúng ta cần phải thực hiện thông qua Admin API trên Prometheus.
Trước tiên chúng ta cần chạy lại Prometheus bằng lệnh sau đển bật tính năng “Admin API“:
./prometheus --config.file prometheus.yml --web.enable-admin-apiSau đó chúng ta chạy lệnh sau trên server chạy Prometheus để xóa dữ liệu cho instance “server-tracking-01“:
curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={instance="server-tracking-01:9100"}'Tham khảo:

















Trả lời